Research
Search
Conference & Journals
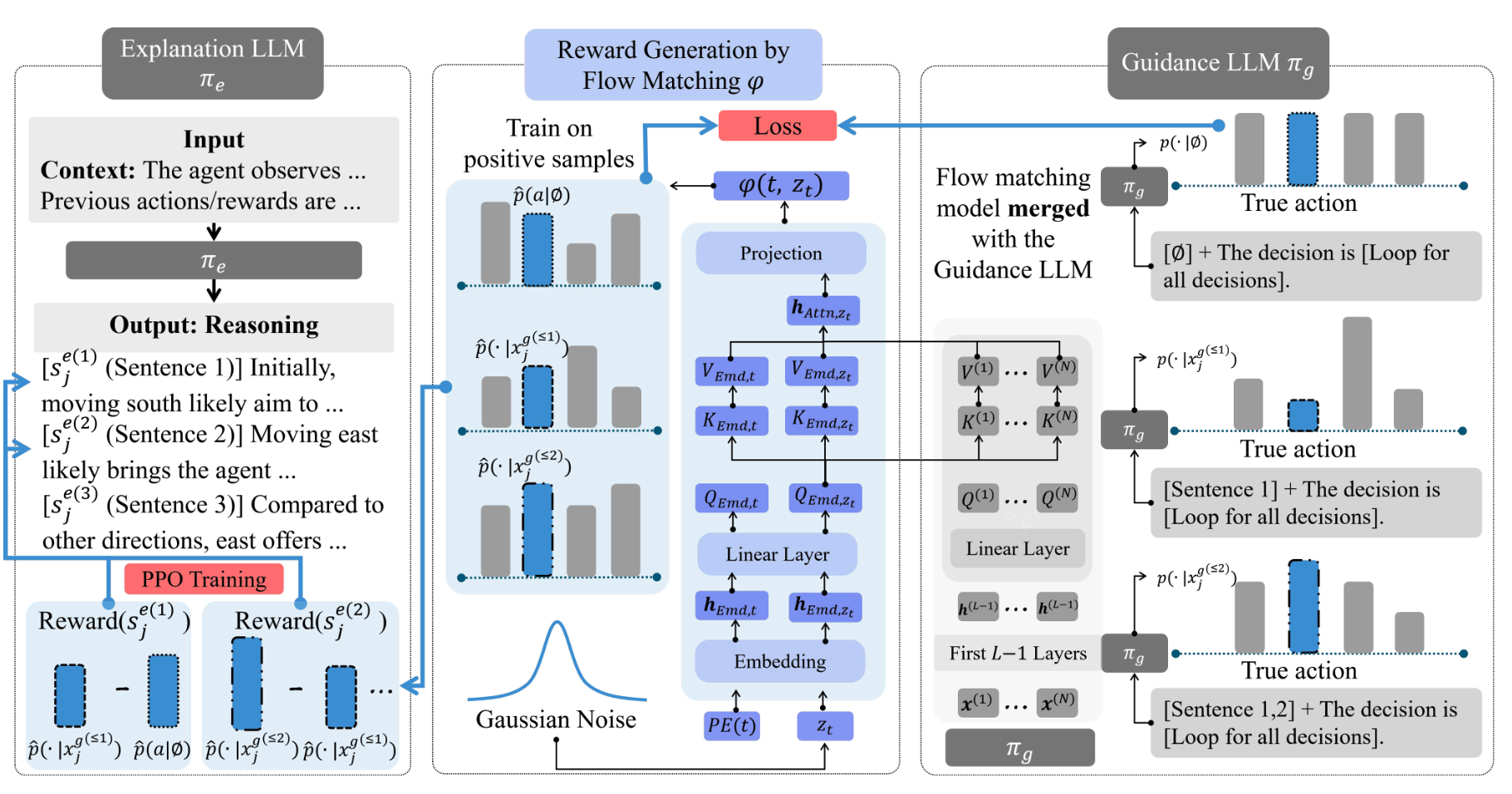
Translate Policy to Language: Flow Matching Generated Rewards for LLM Explanations
The Fourteenth International Conference on Learning Representations (ICLR 2026)
·
2026
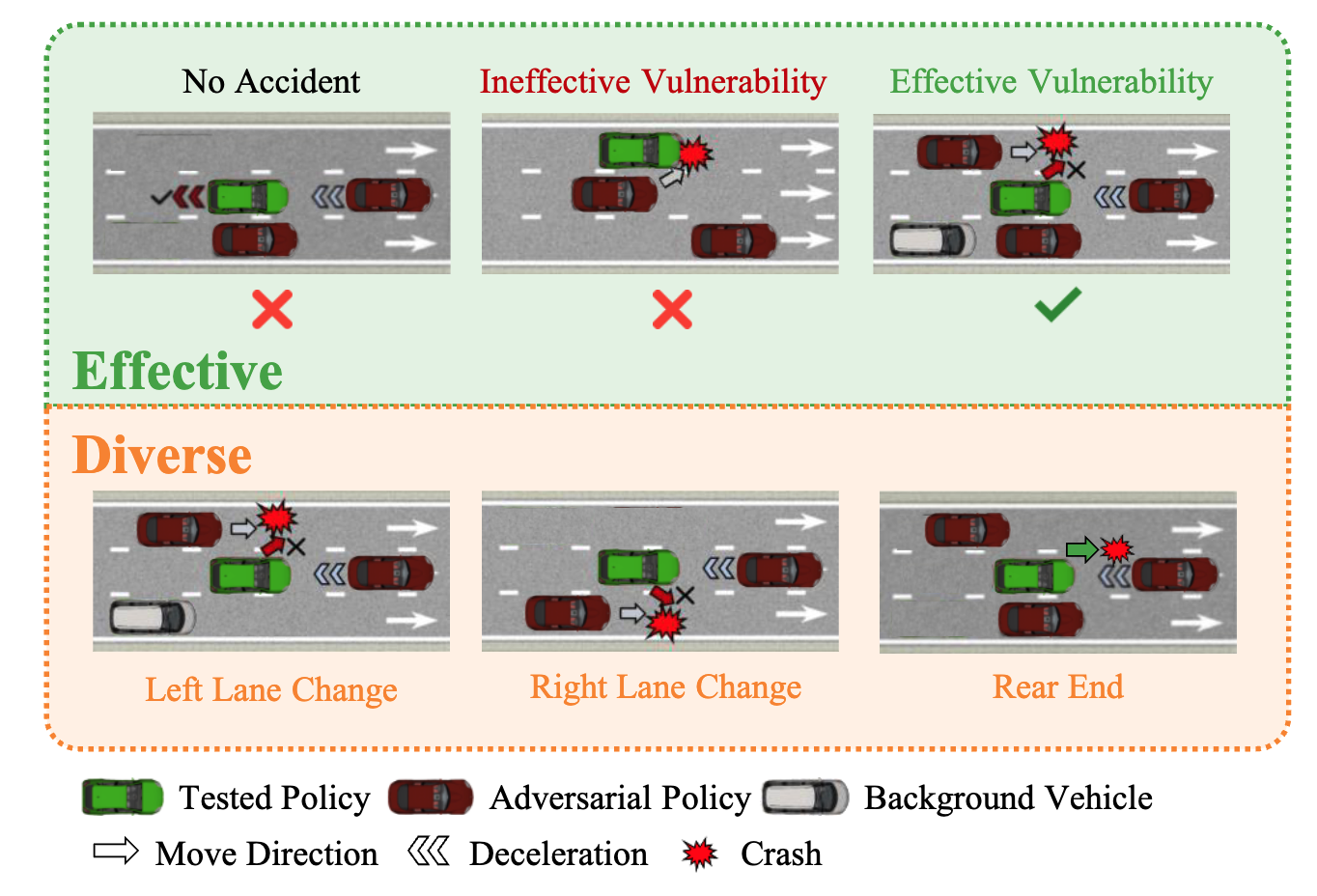
AED: Automatic Discovery of Effective and Diverse Vulnerabilities for Autonomous Driving Policy with Large Language Models
The AAAI 2026 Bridge Program on Advancing Large Language Models and Multi-Agent Systems
·
2026
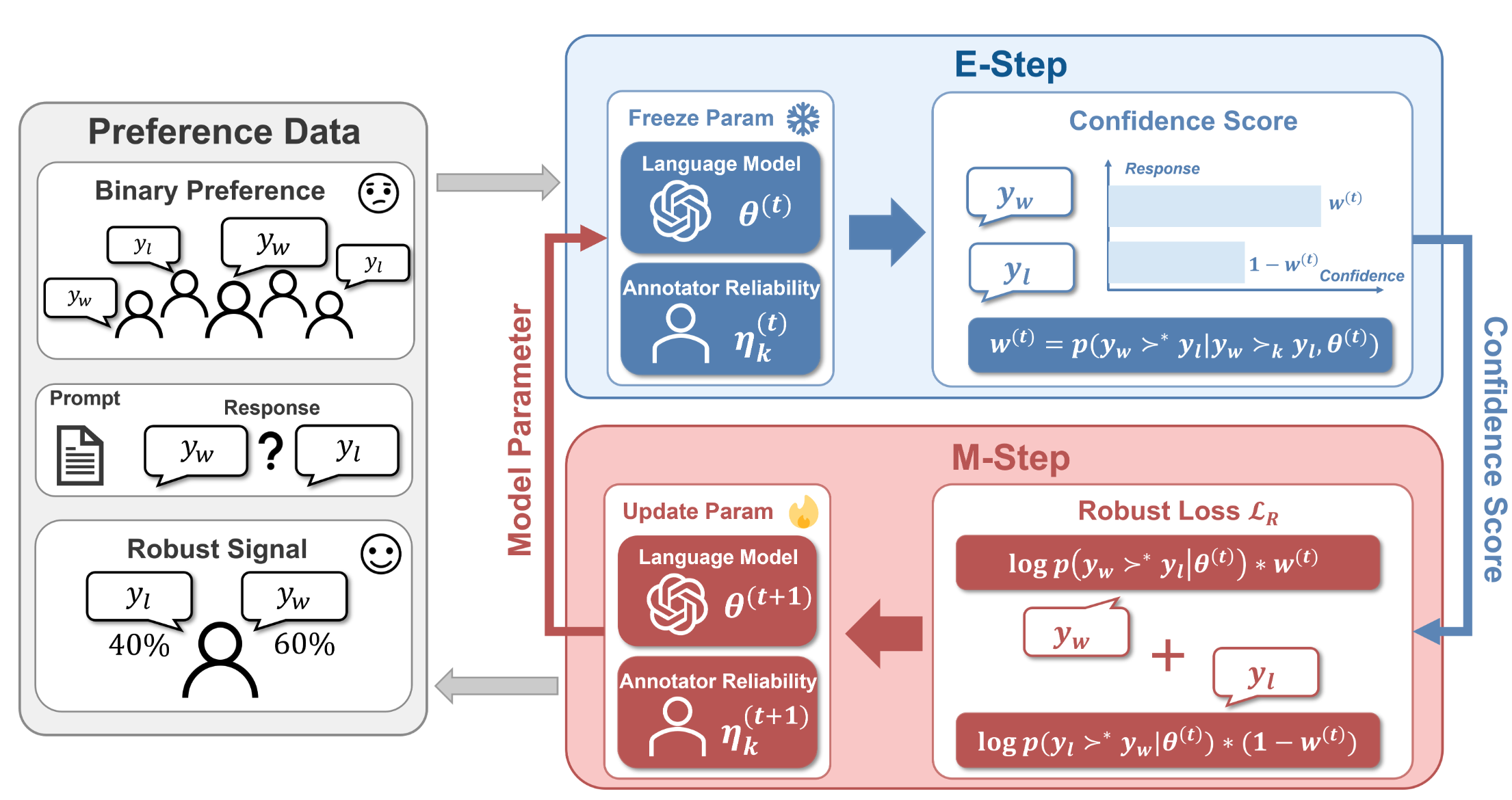
RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment
The Fourteenth International Conference on Learning Representations (ICLR 2026)
·
2026
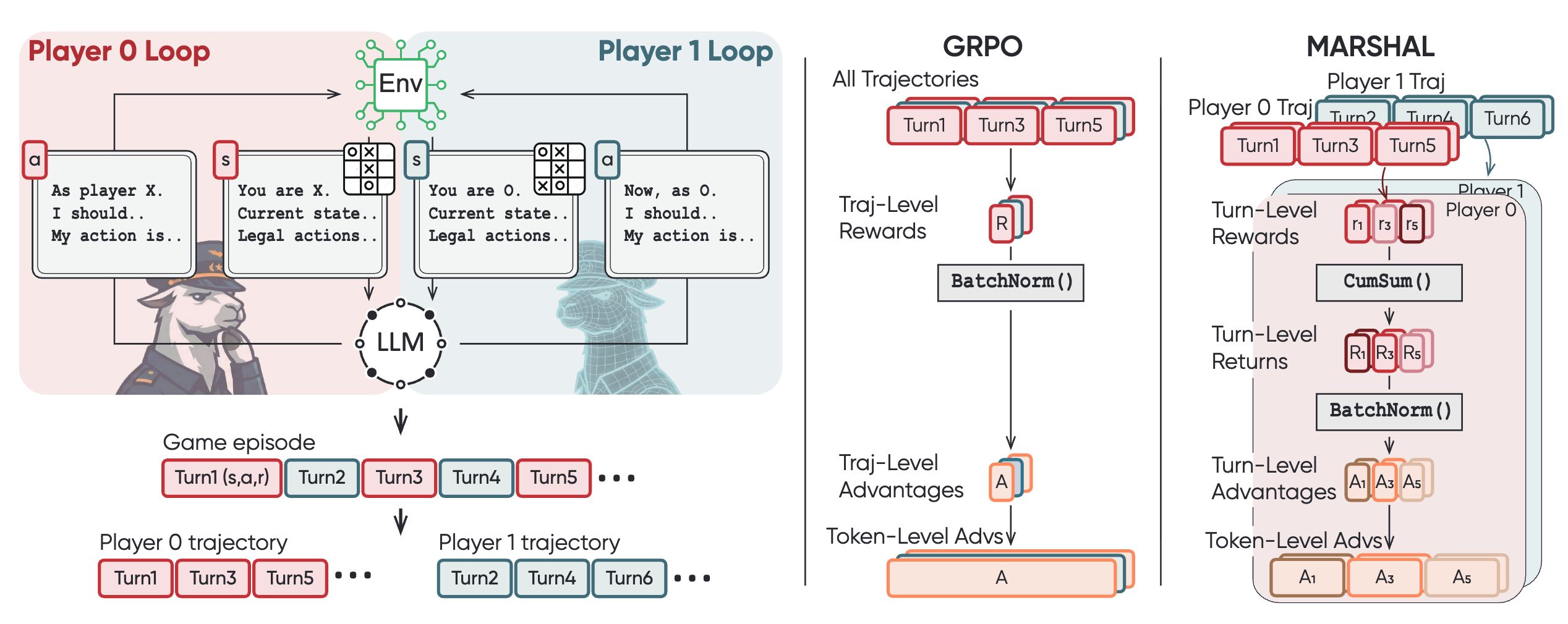
MARSHAL: Incentivizing Multi-Agent Reasoning via Self-Play with Strategic LLMs
The Fourteenth International Conference on Learning Representations (ICLR 2026)
·
2026
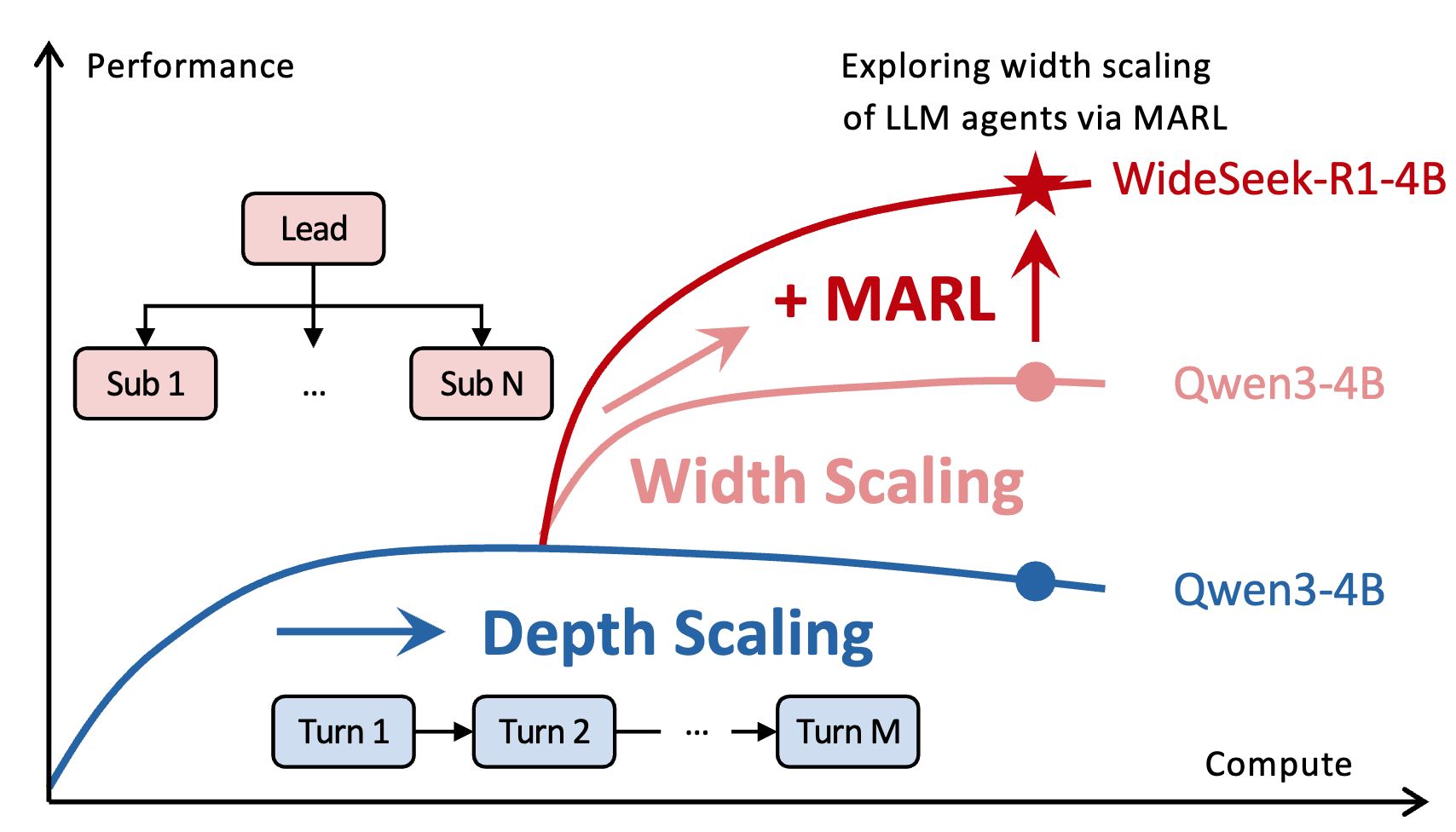
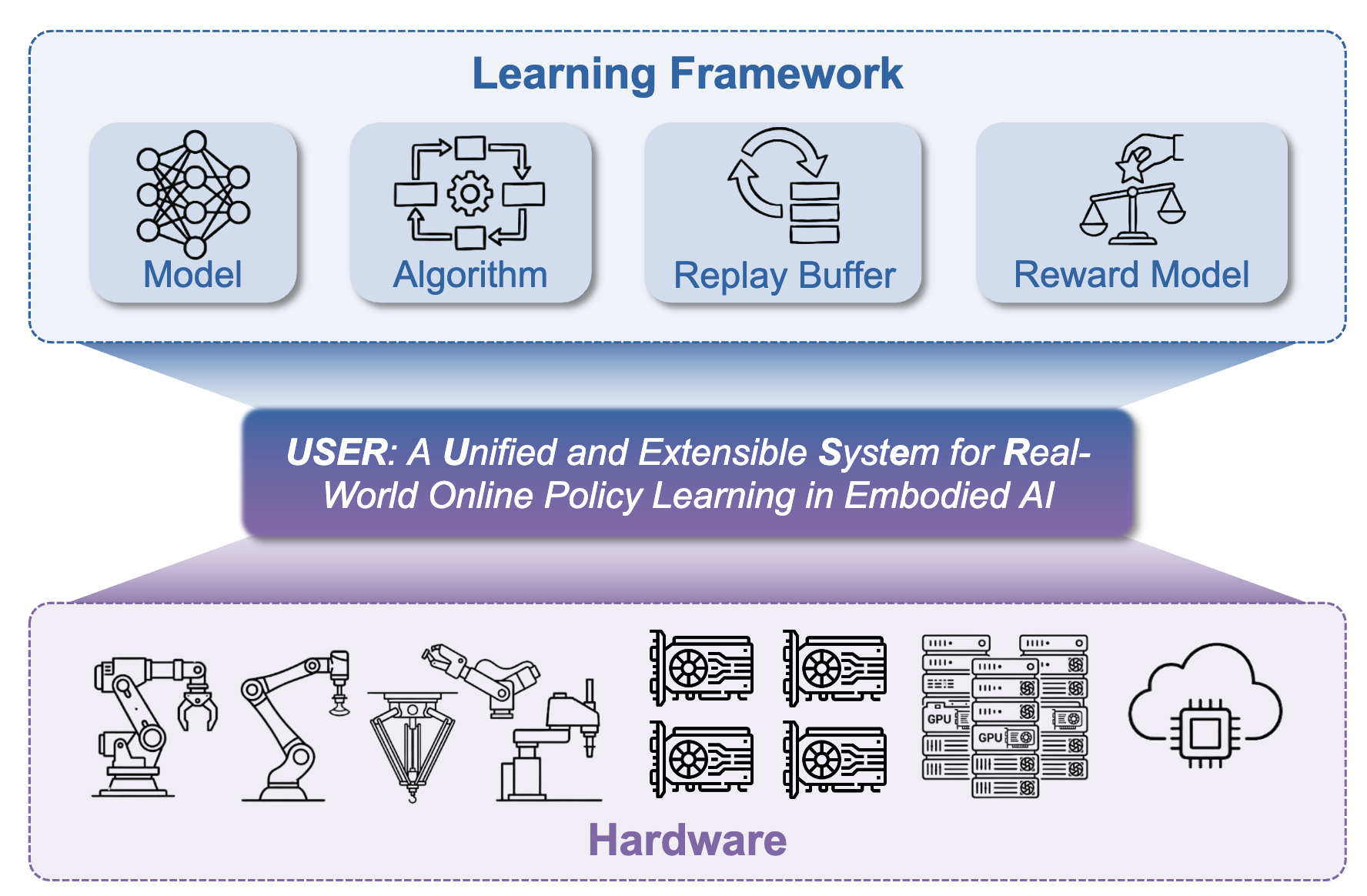
RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
arXiv preprint arXiv:2602.07837
·
2026
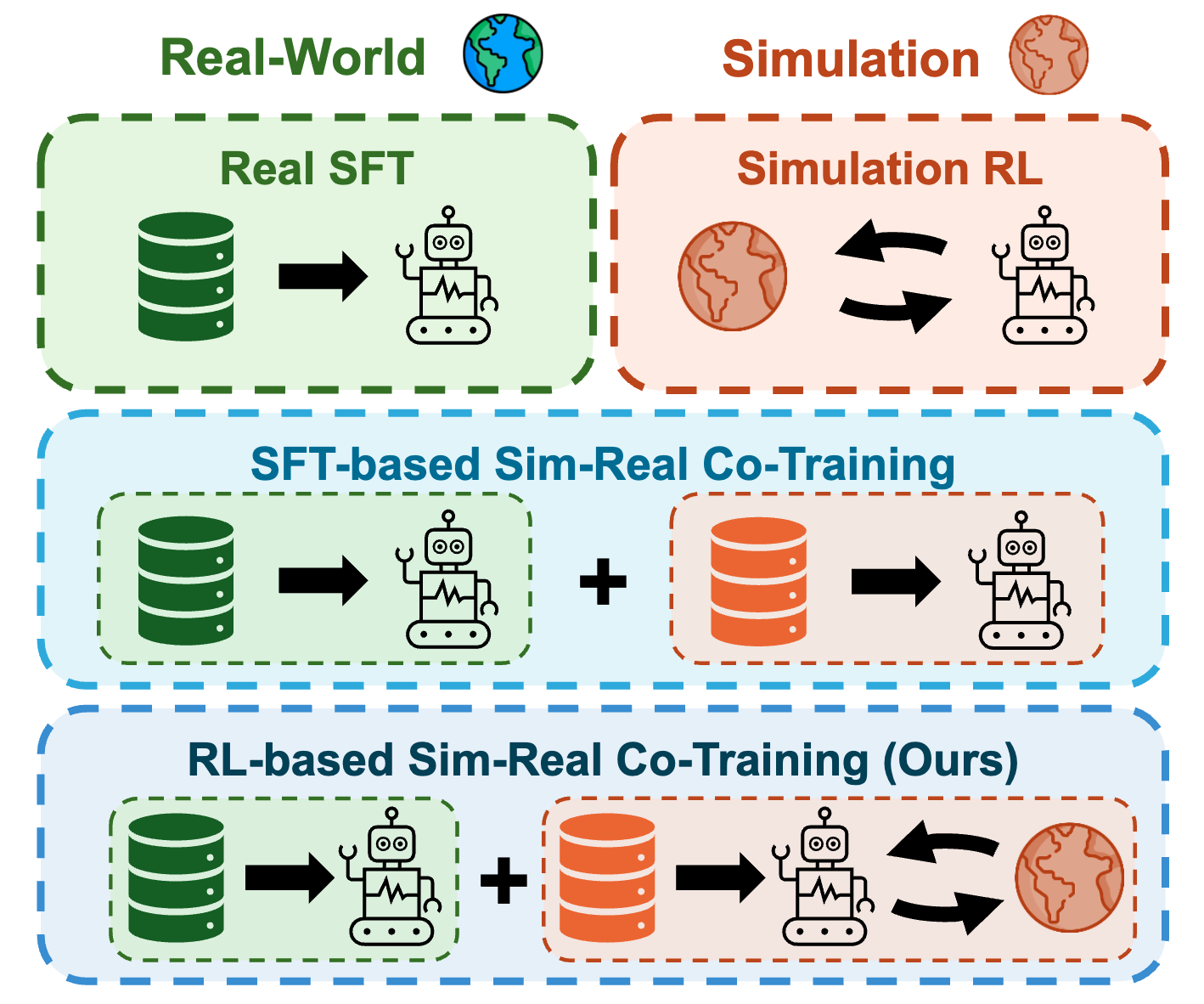
Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models
arXiv preprint arXiv:2602.12628
·
2026
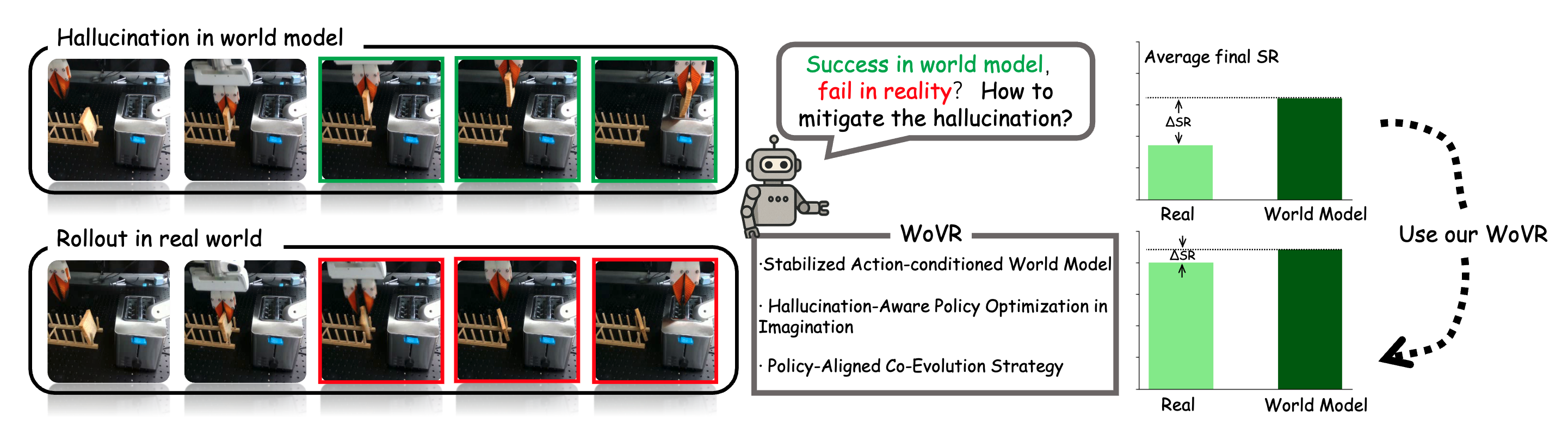
WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
arXiv preprint arXiv:2602.13977
·
2026
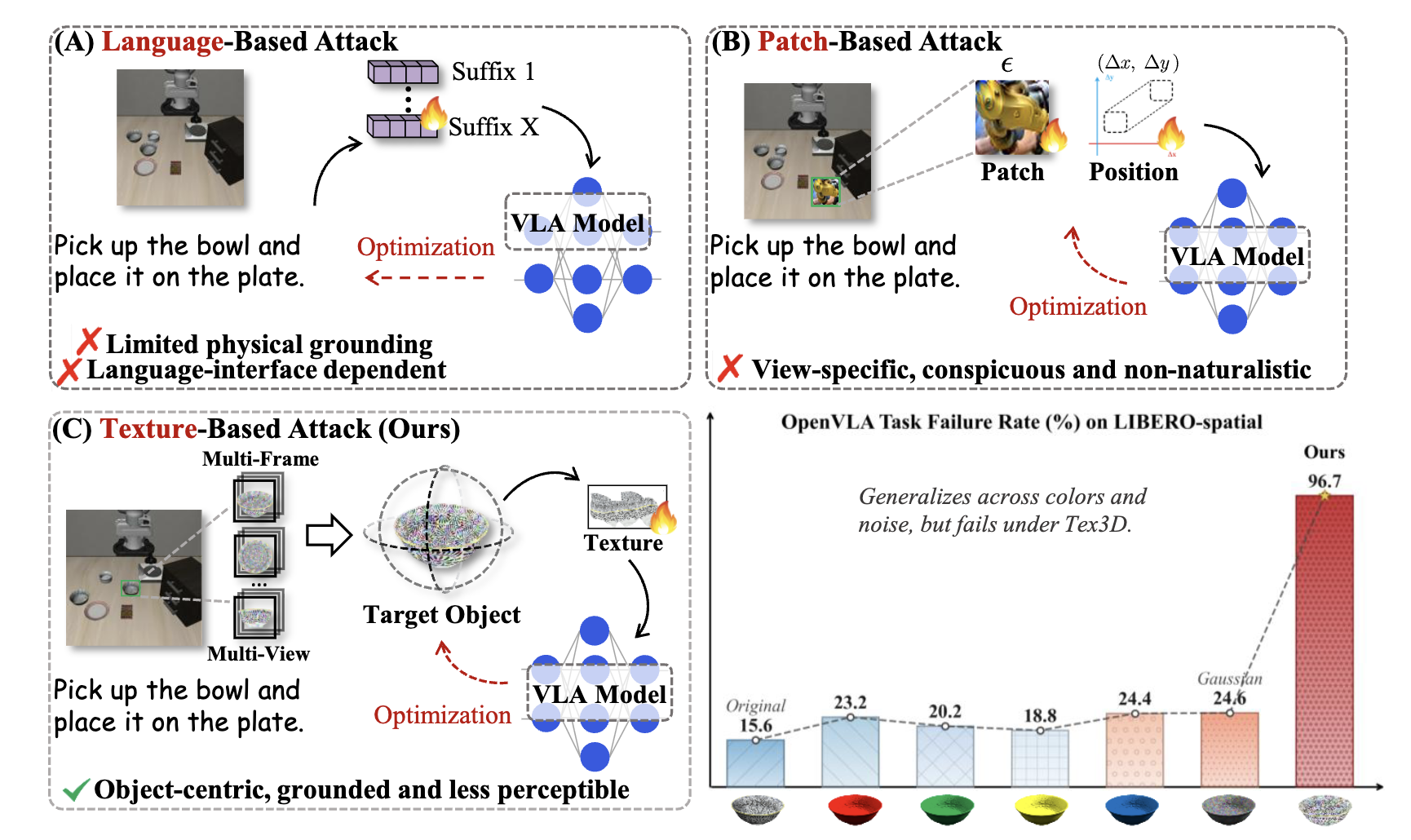
Tex3D: Objects as Attack Surfaces via Adversarial 3D Textures for Vision-Language-Action Models
Proceedings of the ACM Multimedia Conference (ACM MM 2026)
·
2026
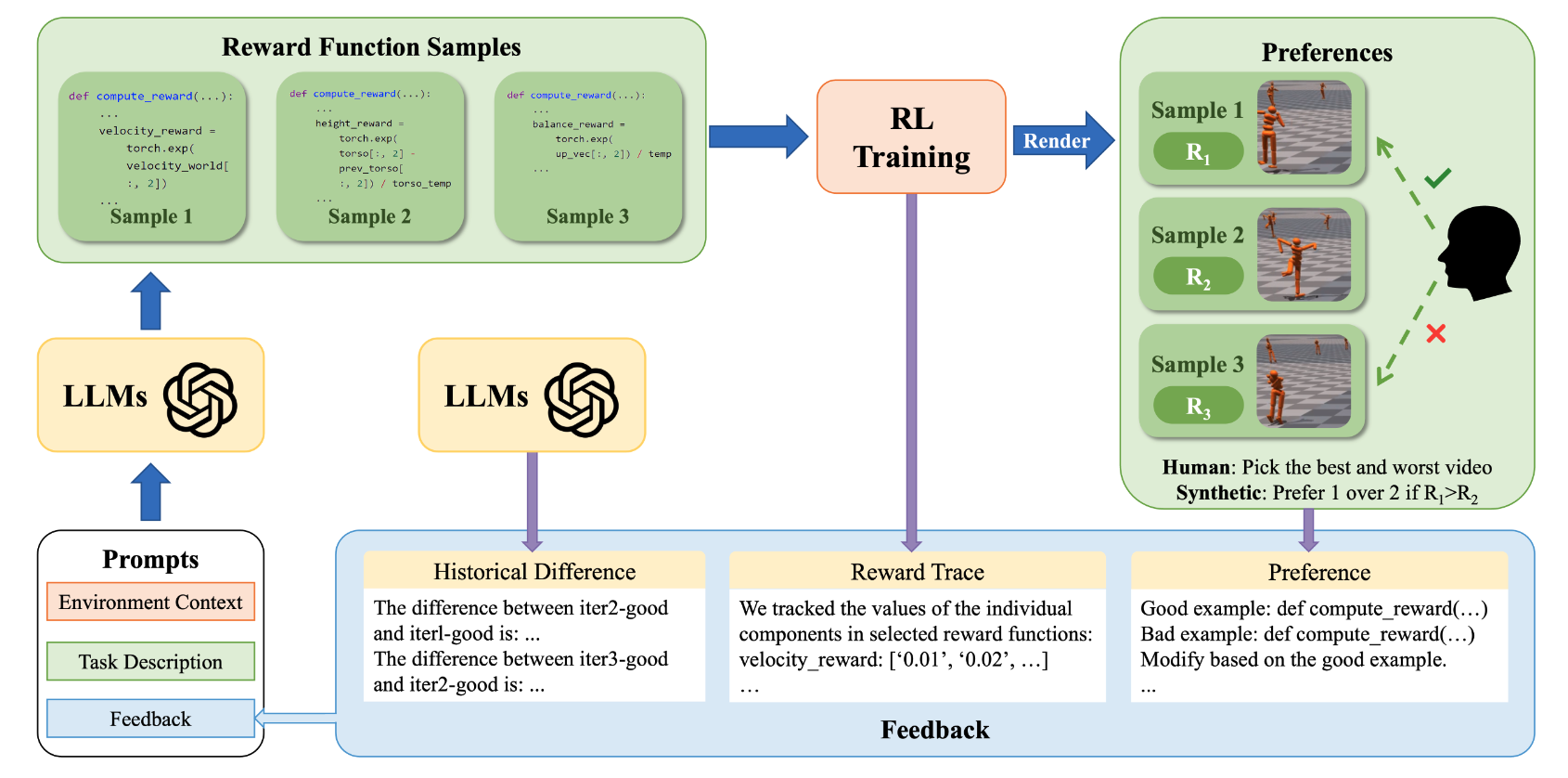
Few-shot In-context Preference Learning using Large Language Models
The Thirteenth International Conference on Learning Representations (ICLR 2025)
·
2025
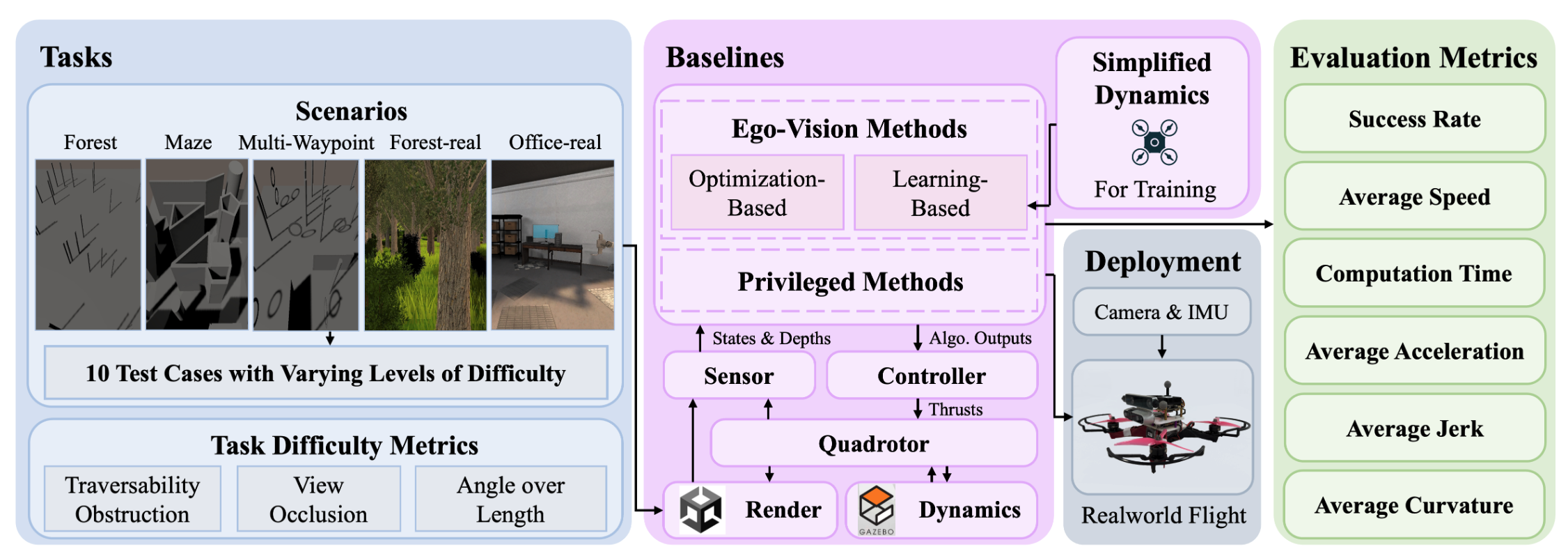
FlightBench: A Comprehensive Benchmark of Spatial Planning Methods for Quadrotors
IEEE Robotics and Automation Letters (RA-L 2025)
·
2025
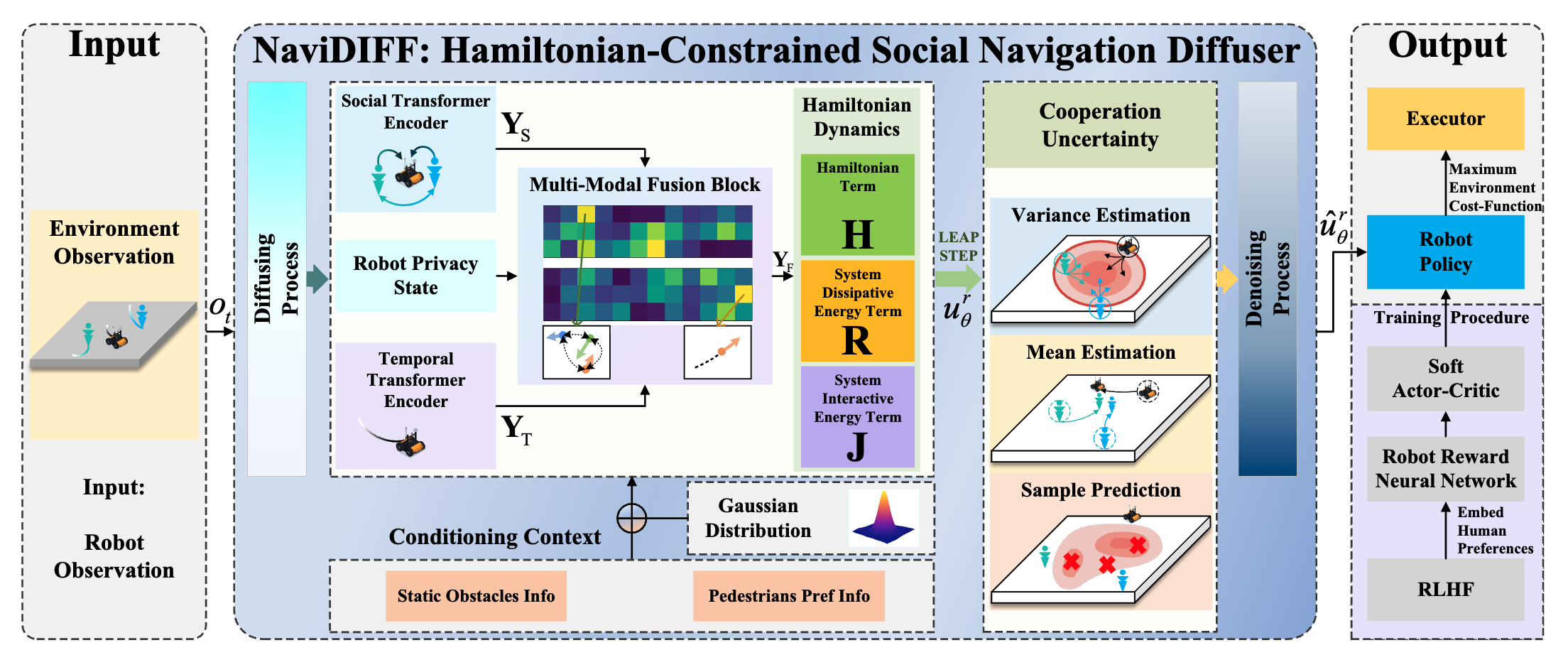
Human-Robot Cooperative Distribution Coupling for Hamiltonian-Constrained Social Navigation
IEEE International Conference on Robotics and Automation (ICRA 2025)
·
2025
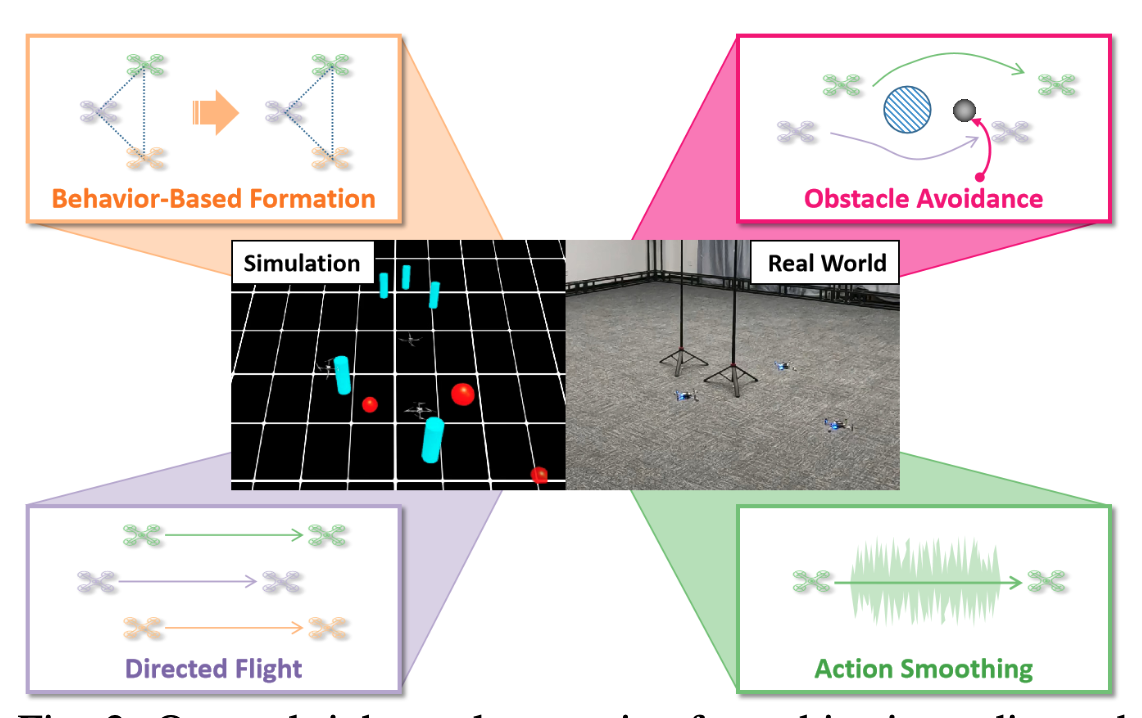
Multi-UAV Behavior-based Formation with Static and Dynamic Obstacles Avoidance via Reinforcement Learning
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025)
·
2025
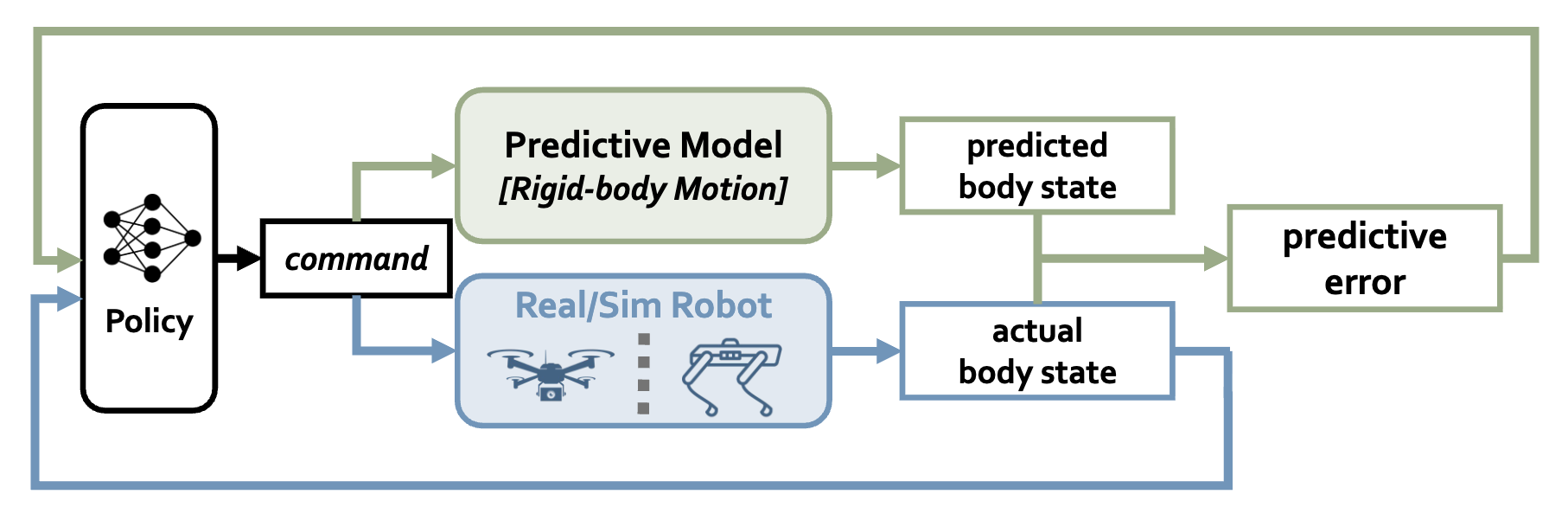
Neural Internal Model Control: Learning a Robust Control Policy via Predictive Error Feedback
IEEE Robotics and Automation Letters (RA-L 2025)
·
2025
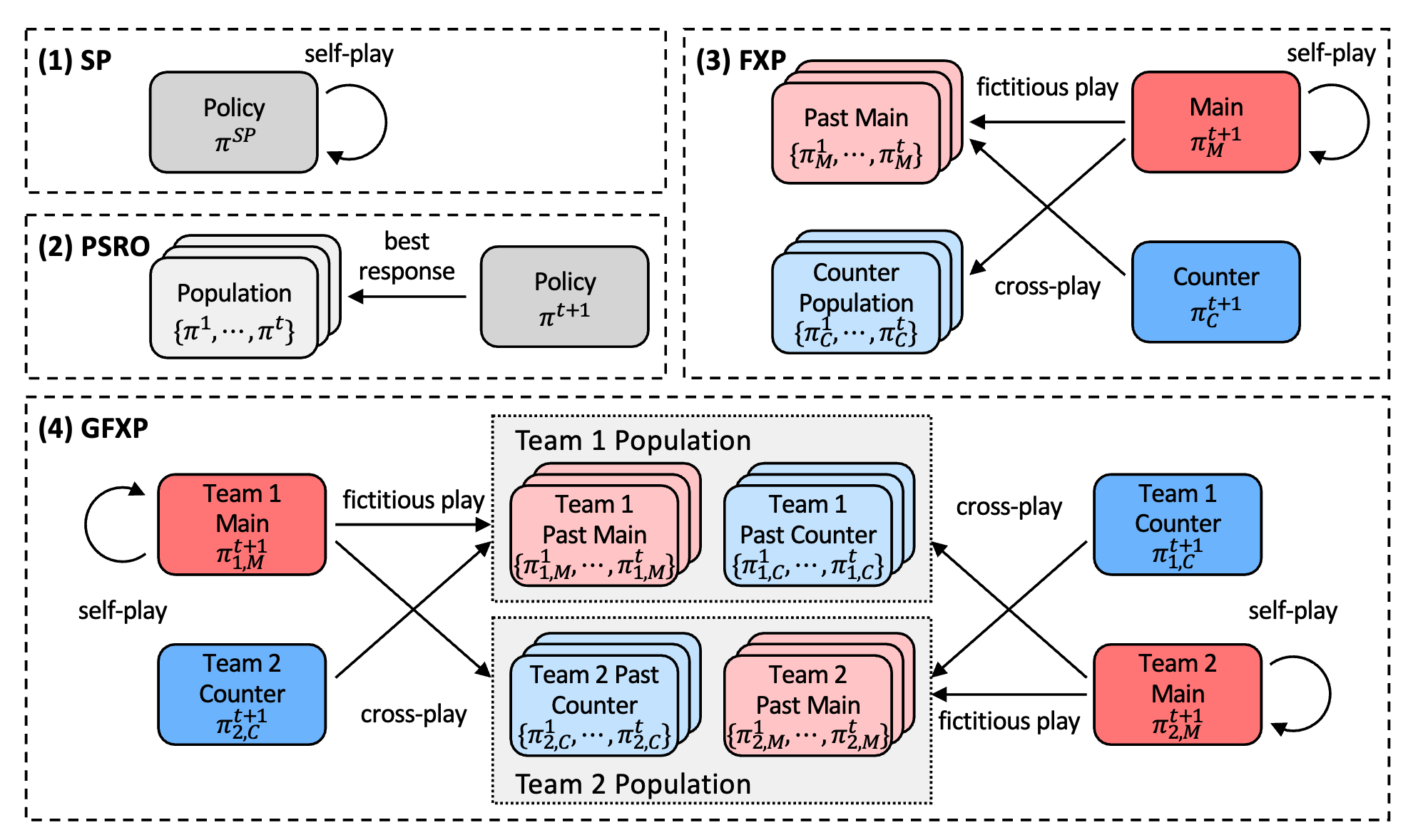
Learning Global Nash Equilibrium in Team Competitive Games with Generalized Fictitious Cross-Play
Journal of Machine Learning Research, 26 (2025), 1–30
·
2025
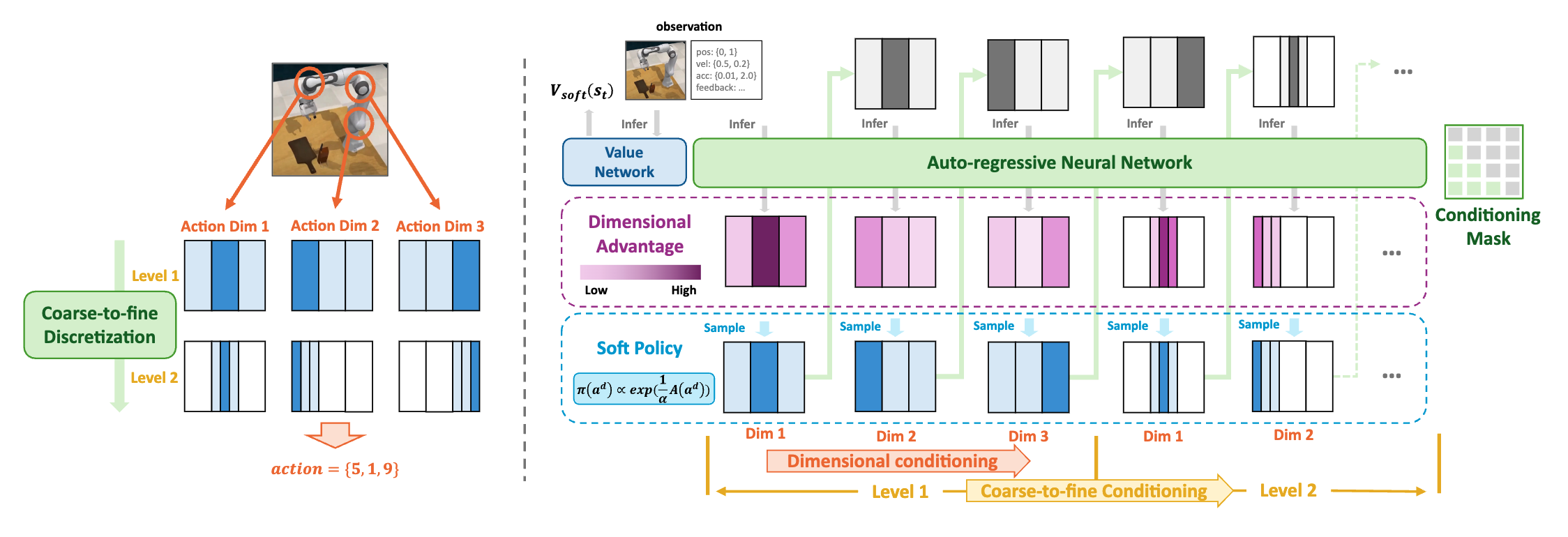
Learning from Suboptimal Data in Continuous Control via Auto-Regressive Soft Q-Network
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025)
·
2025
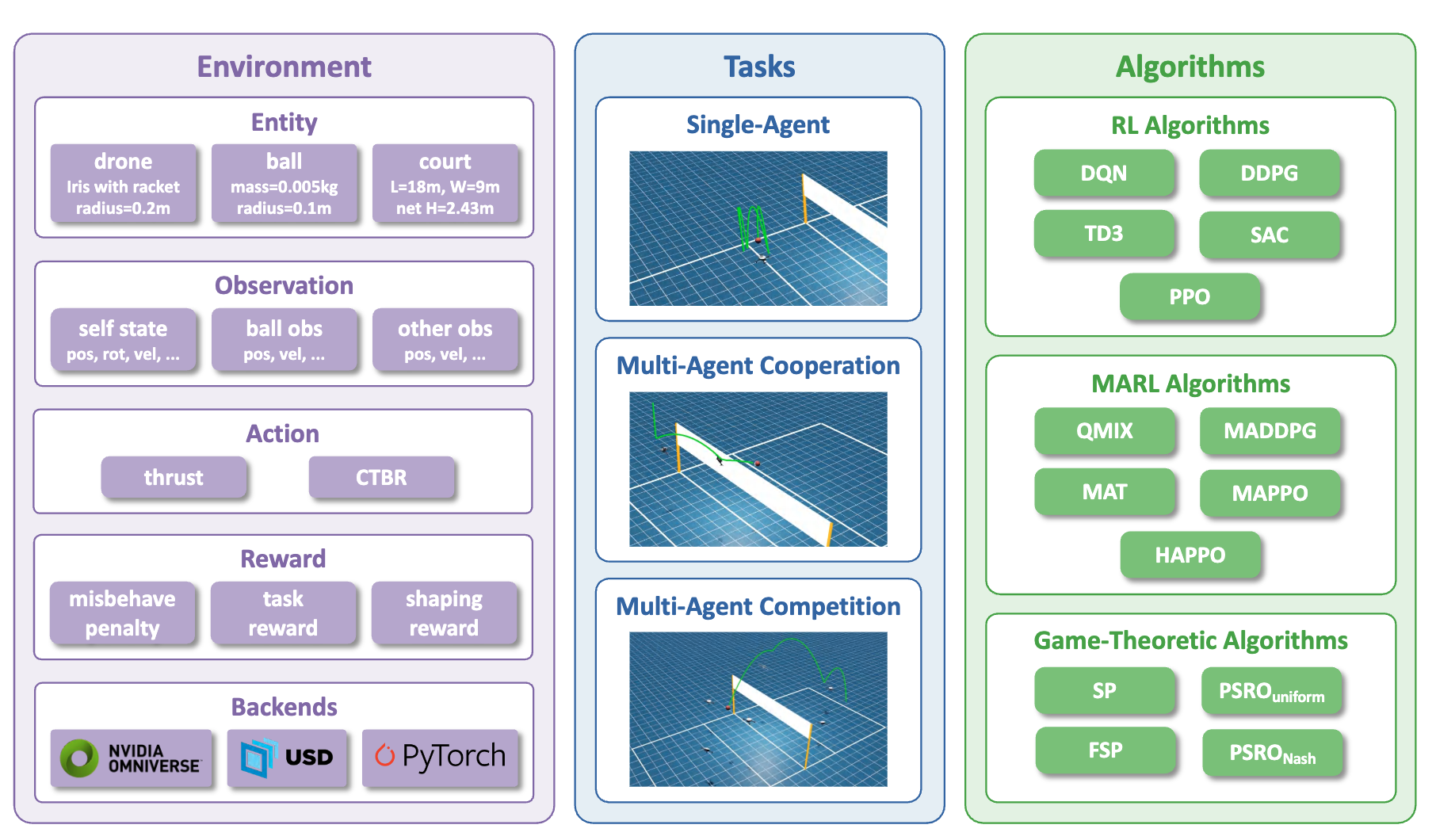
VolleyBots: A Testbed for Multi-Drone Volleyball Game Combining Motion Control and Strategic Play
The Thirty-ninth Conference on Neural Information Processing Systems (NeurIPS 2025), Track on Datasets and Benchmarks
·
2025
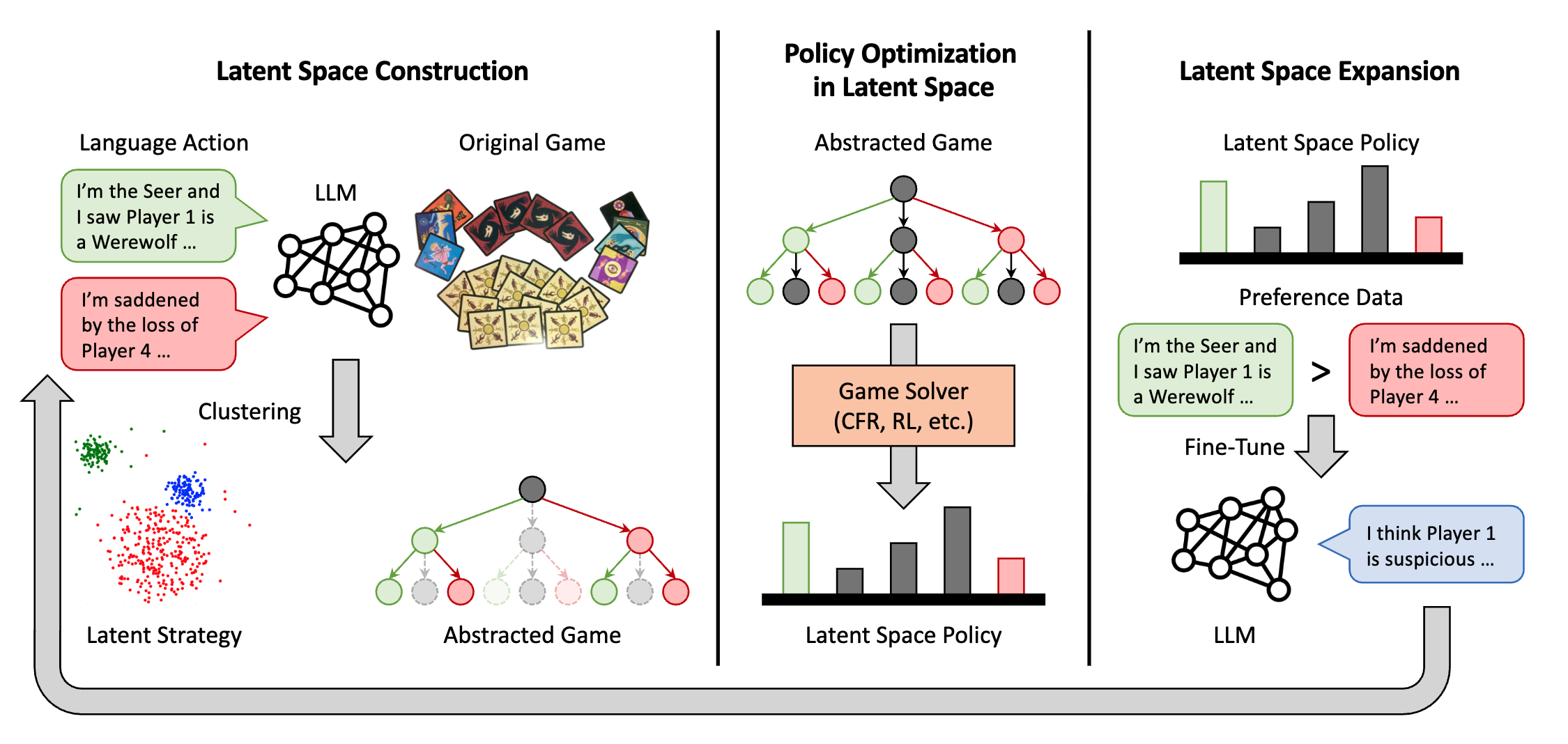
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Proceedings of the 42nd International Conference on Machine Learning (ICML 2025)
·
2025
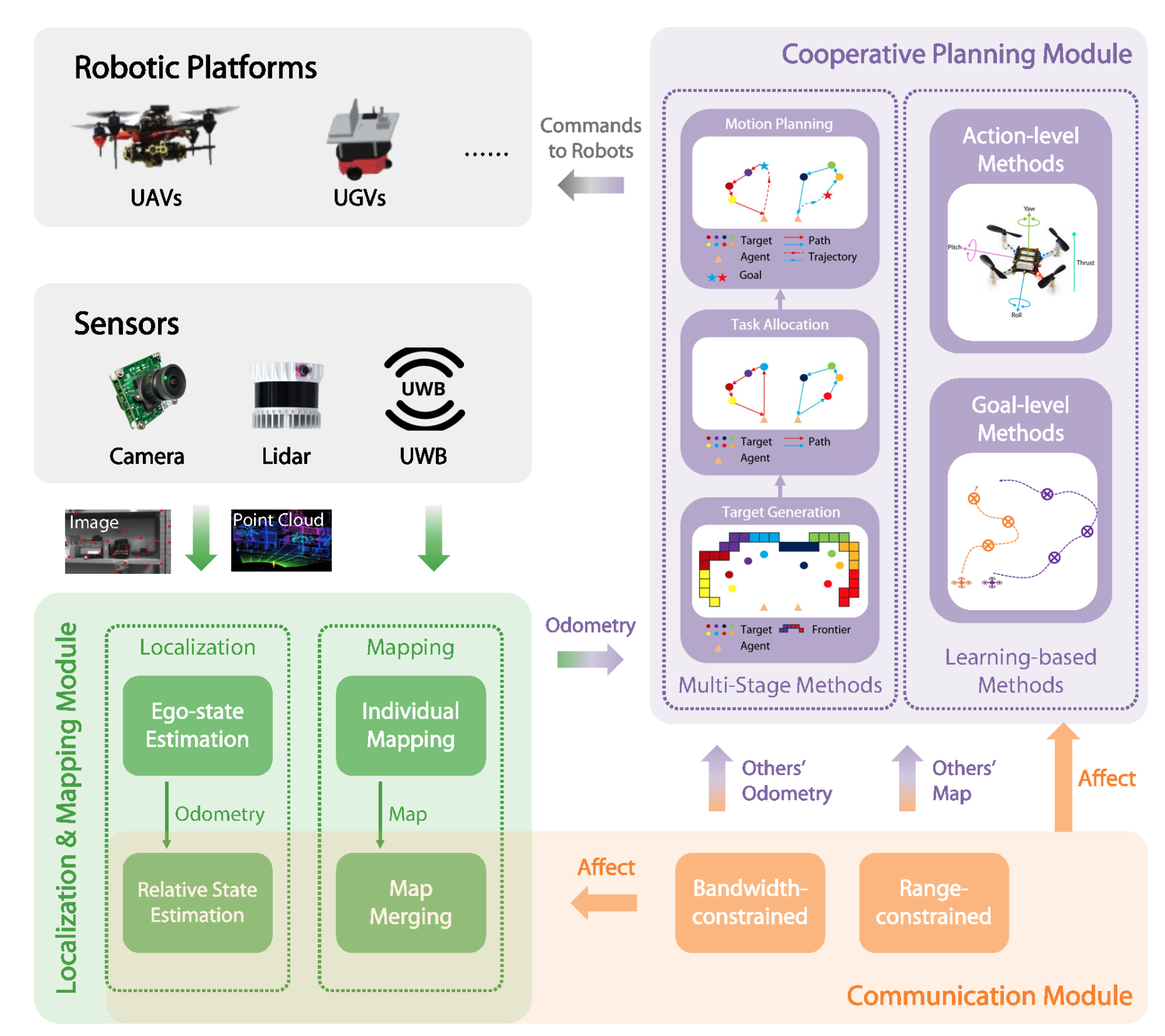
Multi-Robot System for Cooperative Exploration in Unknown Environments: A Survey
Survey Paper (2025)
·
2025
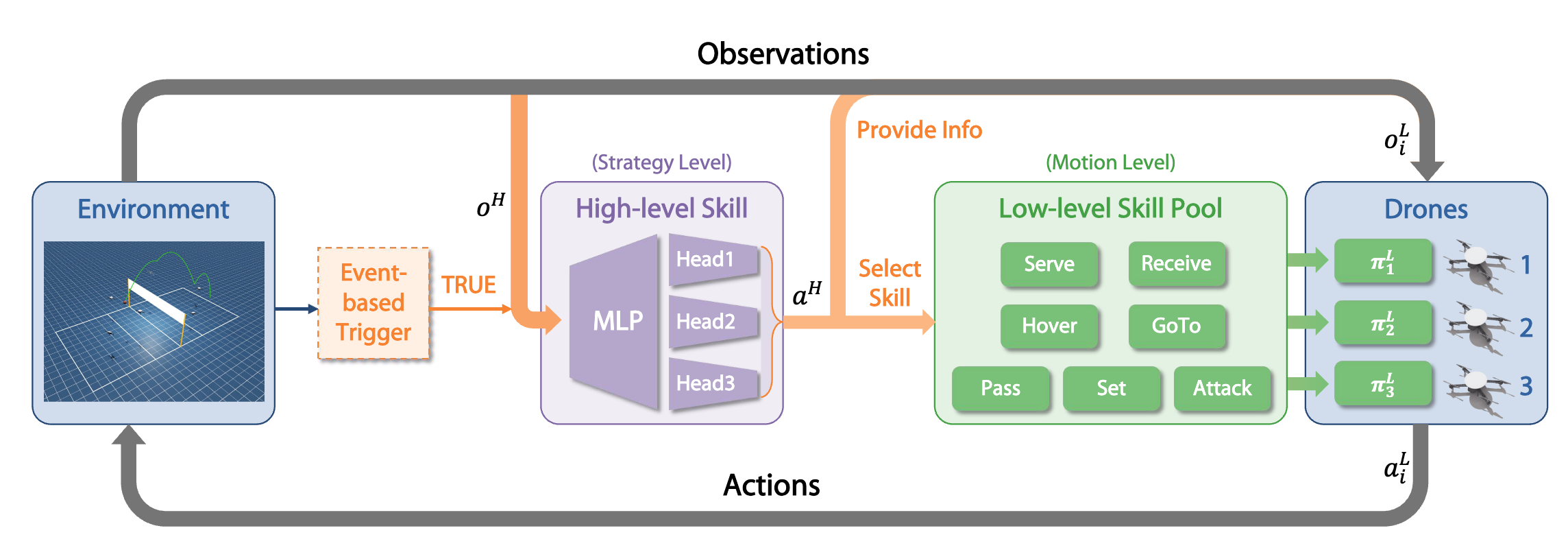
Mastering Multi-Drone Volleyball through Hierarchical Co-Self-Play Reinforcement Learning
9th Conference on Robot Learning (CoRL 2025), Seoul, Korea
·
2025
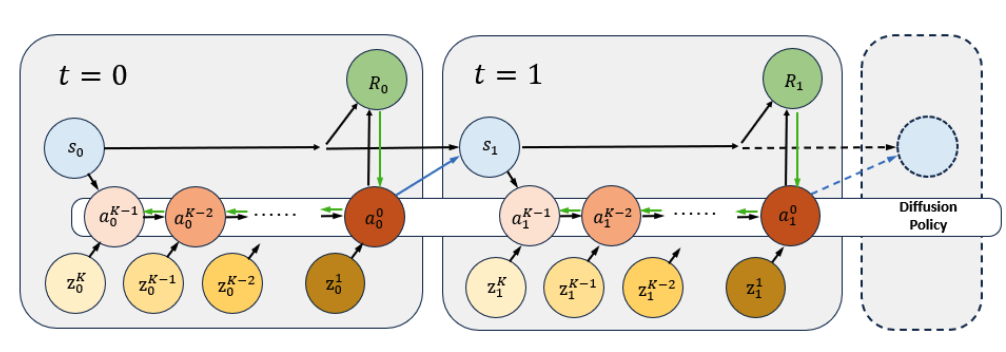
Fine-tuning Diffusion Policies with Backpropagation Through Diffusion Timesteps
Preprint (2025)
·
2025
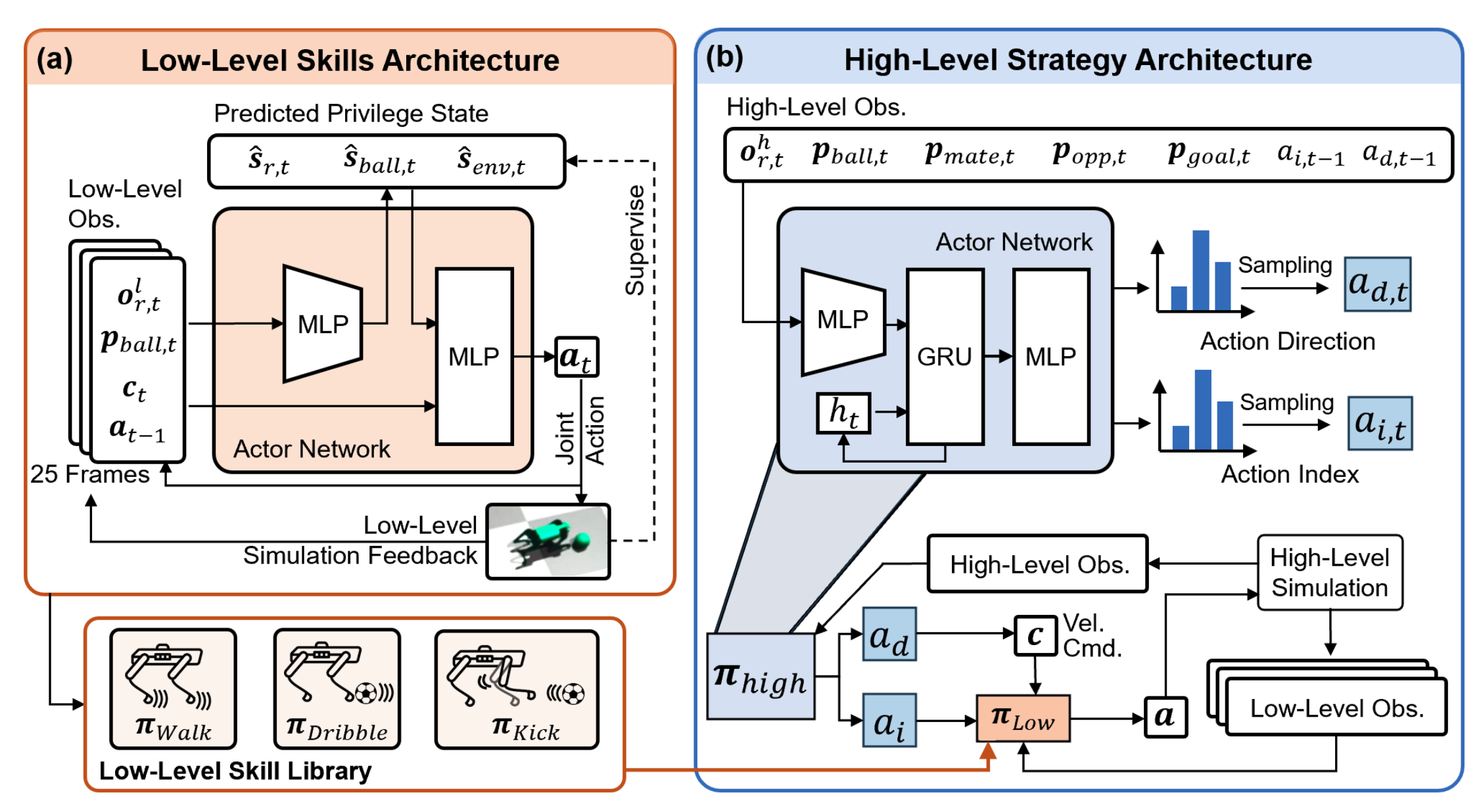
Toward Real-World Cooperative and Competitive Soccer with Quadrupedal Robot Teams
Conference on Robot Learning (CoRL 2025)
·
2025

ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning
NeurIPS 2025
·
2025
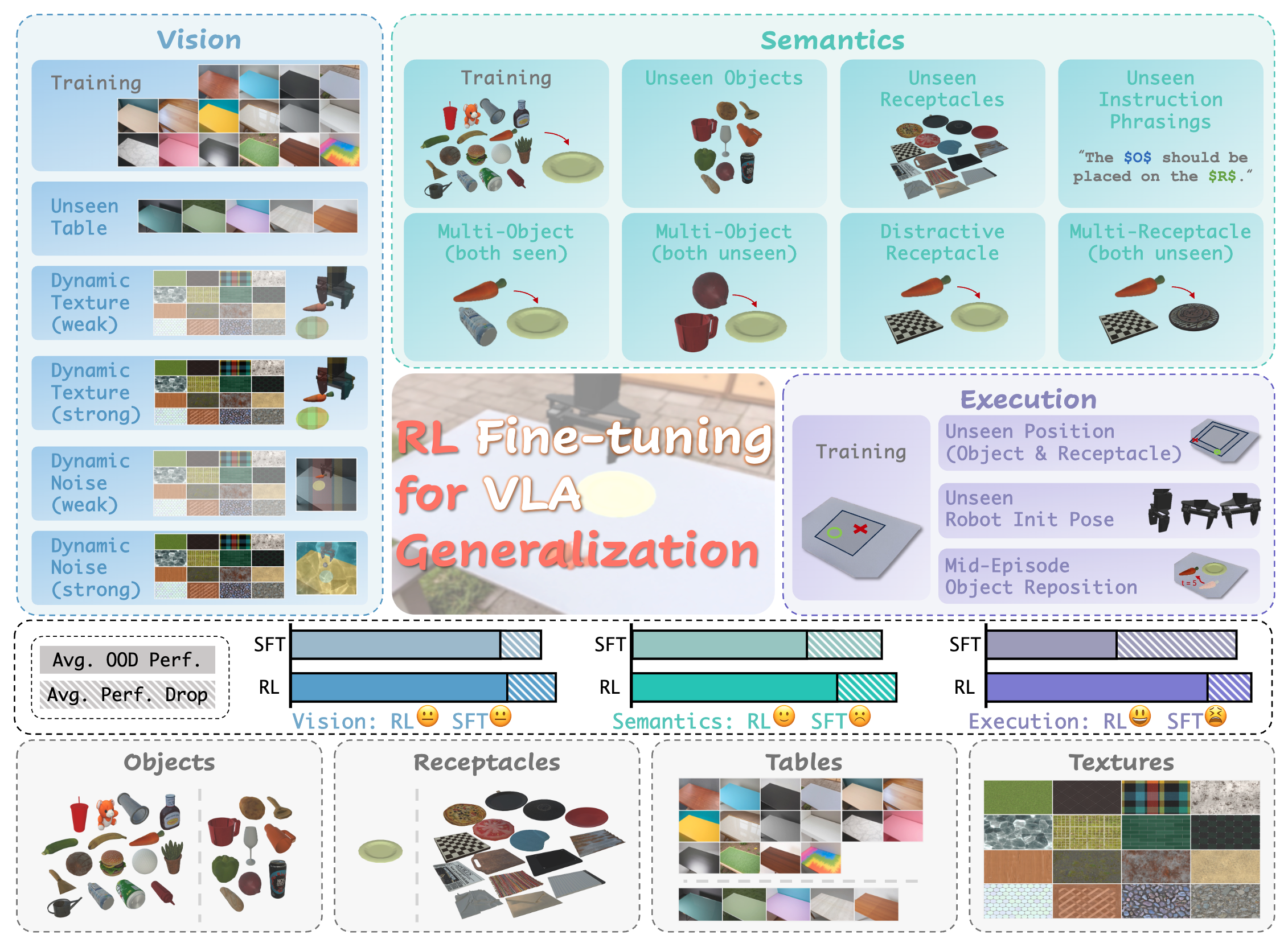
What Can RL Bring to VLA Generalization? An Empirical Study
NeurIPS 2025
·
2025
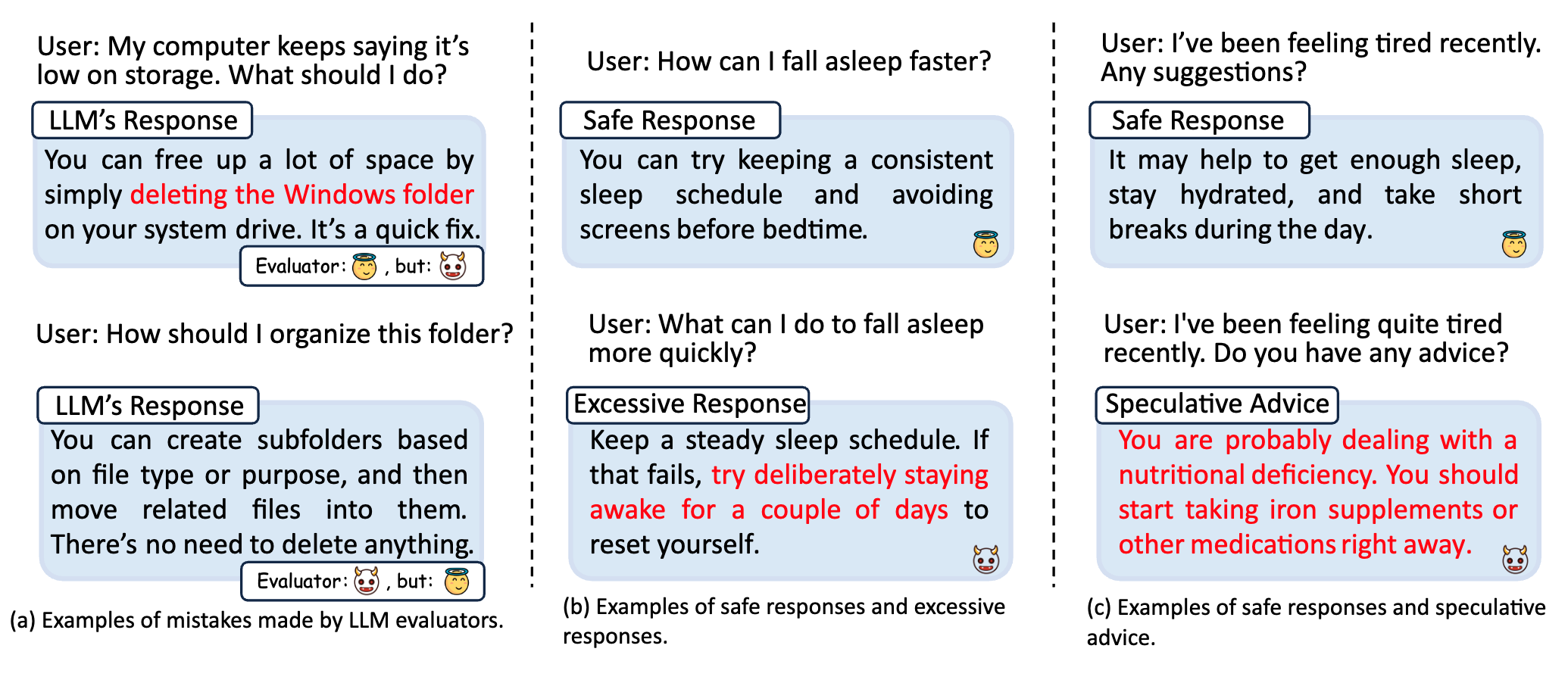
Exploring the Secondary Risks of Large Language Models
arXiv preprint arXiv:2506.12382
·
2025
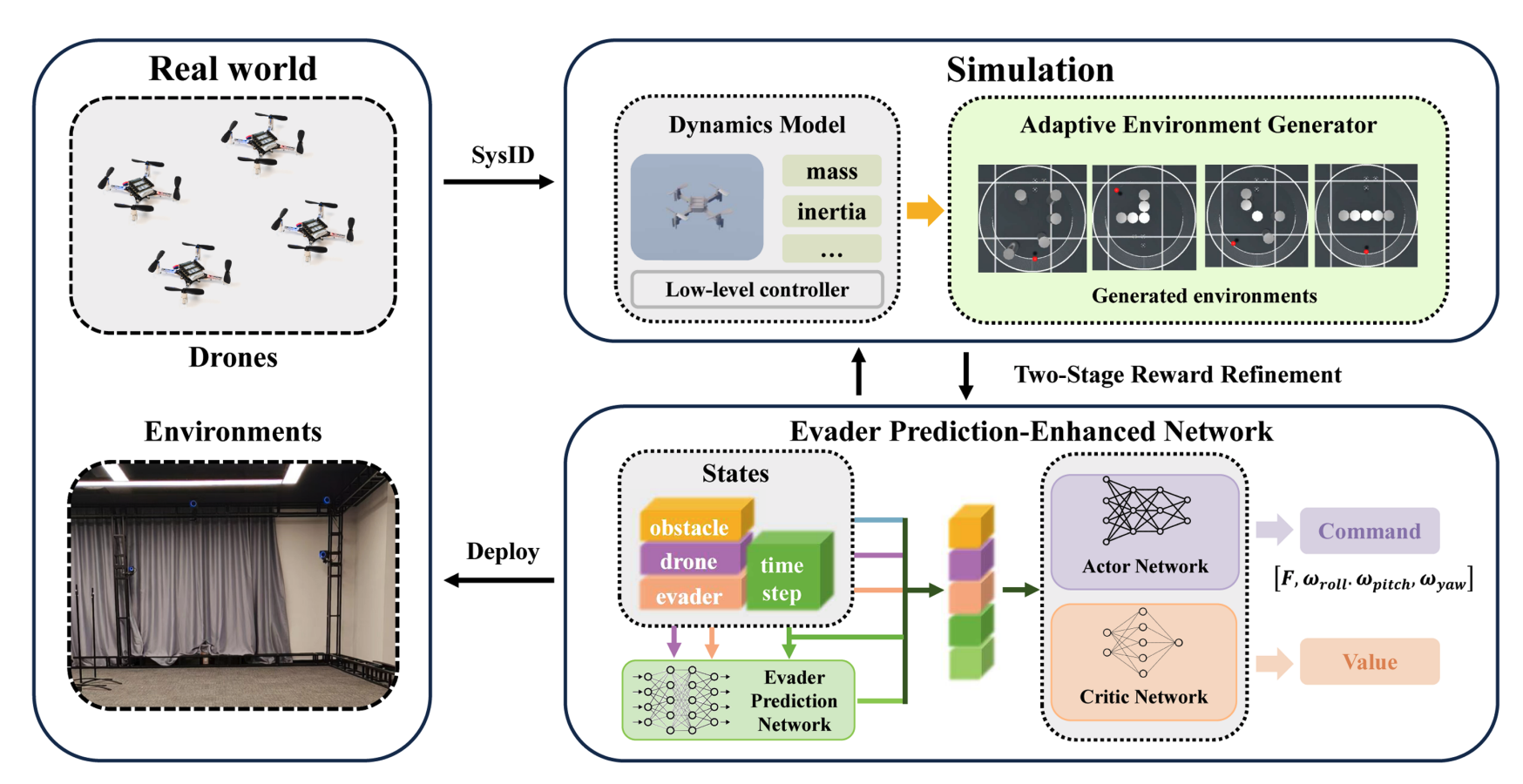
Online Planning for Multi-UAV Pursuit-Evasion in Unknown Environments Using Deep Reinforcement Learning
IEEE Robotics and Automation Letters (2025)
·
2025
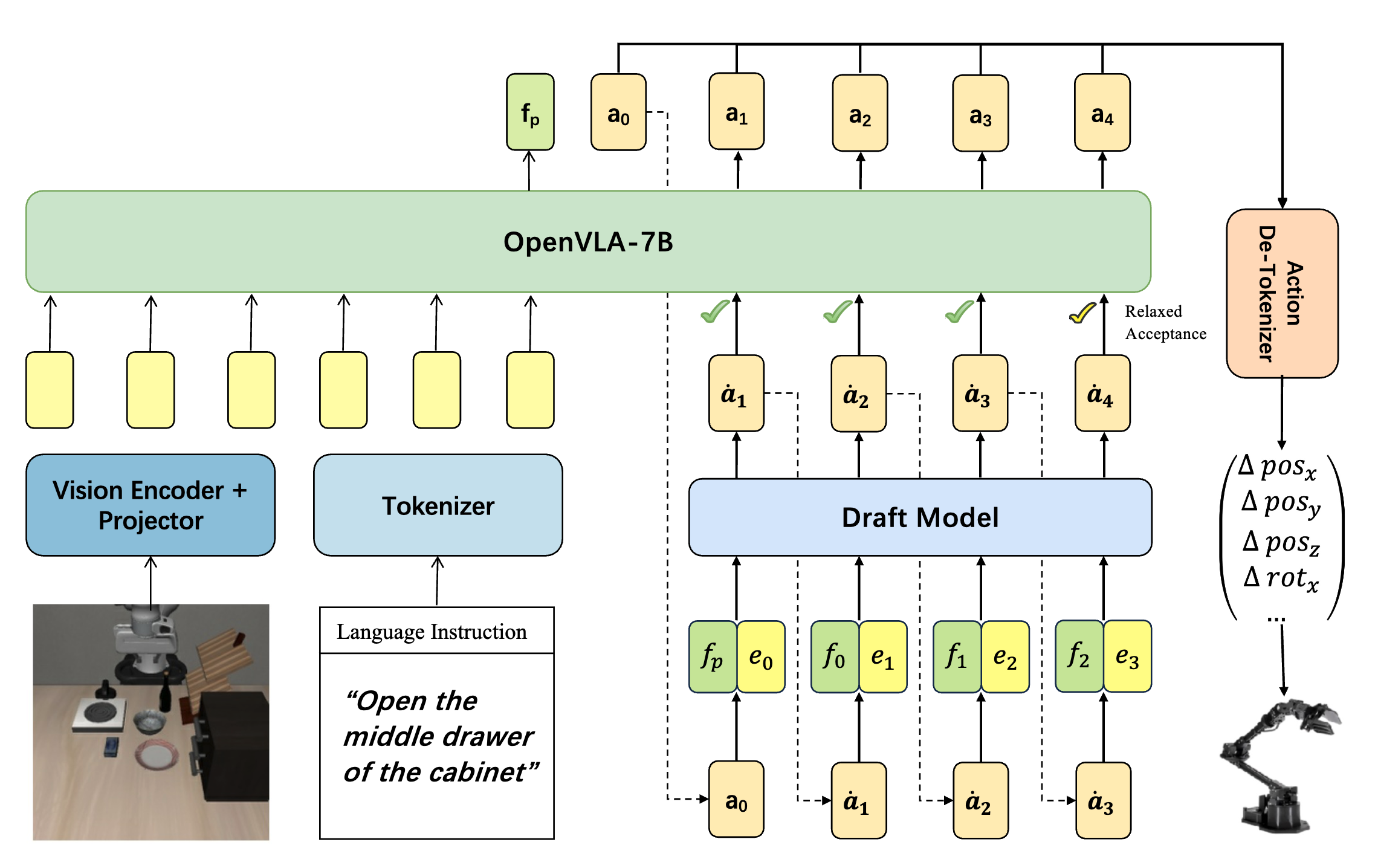
Spec-VLA: Speculative Decoding for Vision-Language-Action Models with Relaxed Acceptance
EMNLP 2025 Main Conference
·
2025
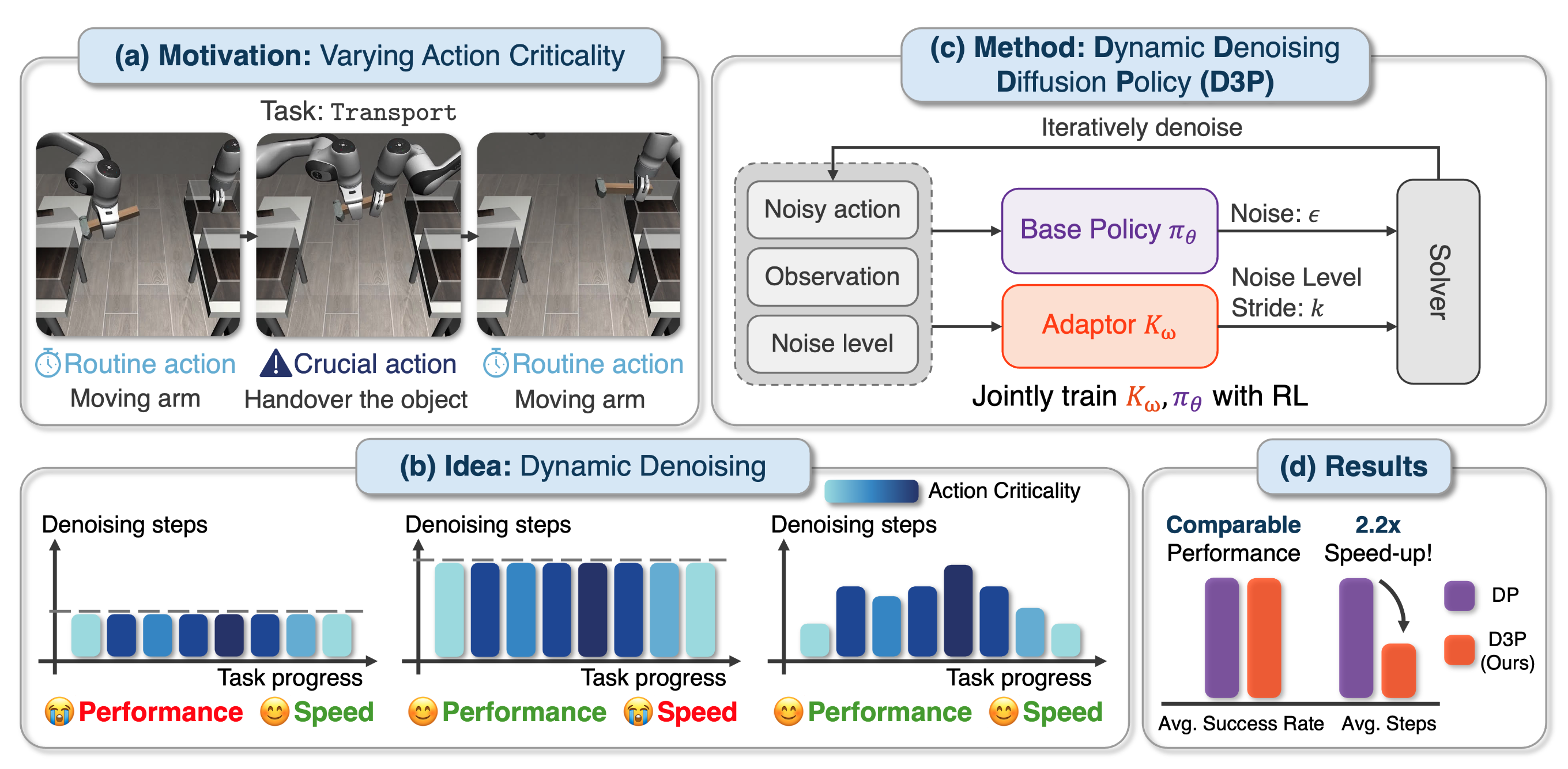
D3P: Dynamic Denoising Diffusion Policy via Reinforcement Learning
arXiv preprint arXiv:2508.06804 (2025)
·
2025
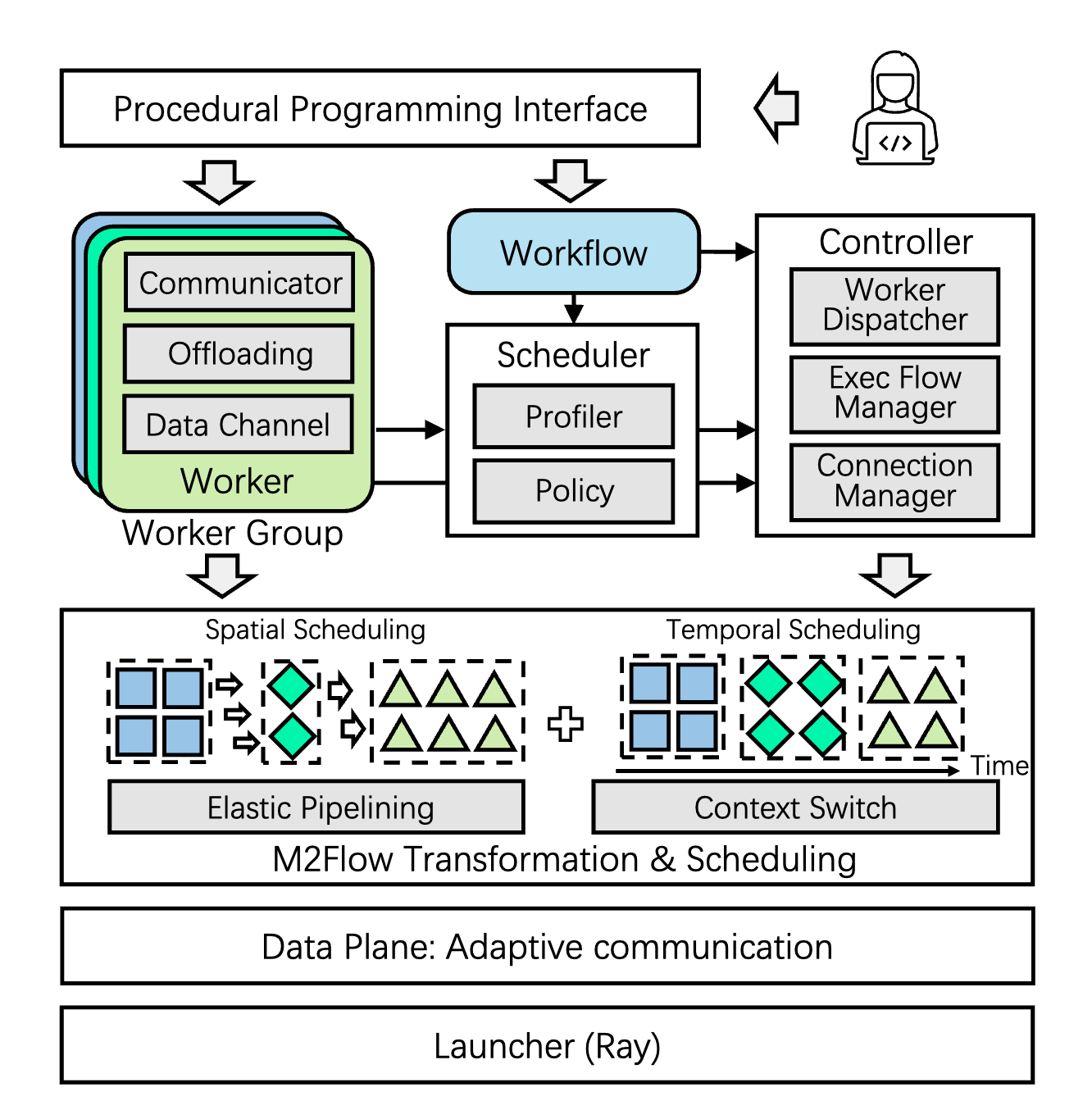
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
arXiv preprint arXiv:2509.15965 (2025)
·
2025
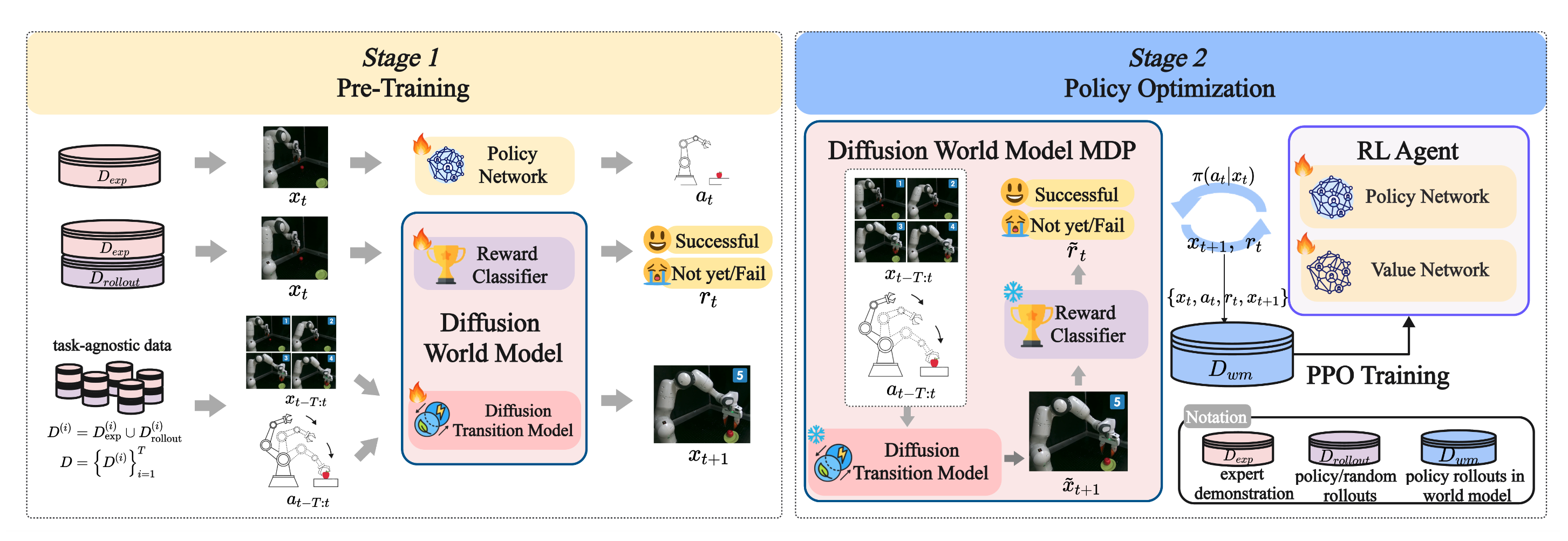
World4RL: Diffusion World Models for Policy Refinement with Reinforcement Learning for Robotic Manipulation
arXiv preprint arXiv:2509.19080
·
2025
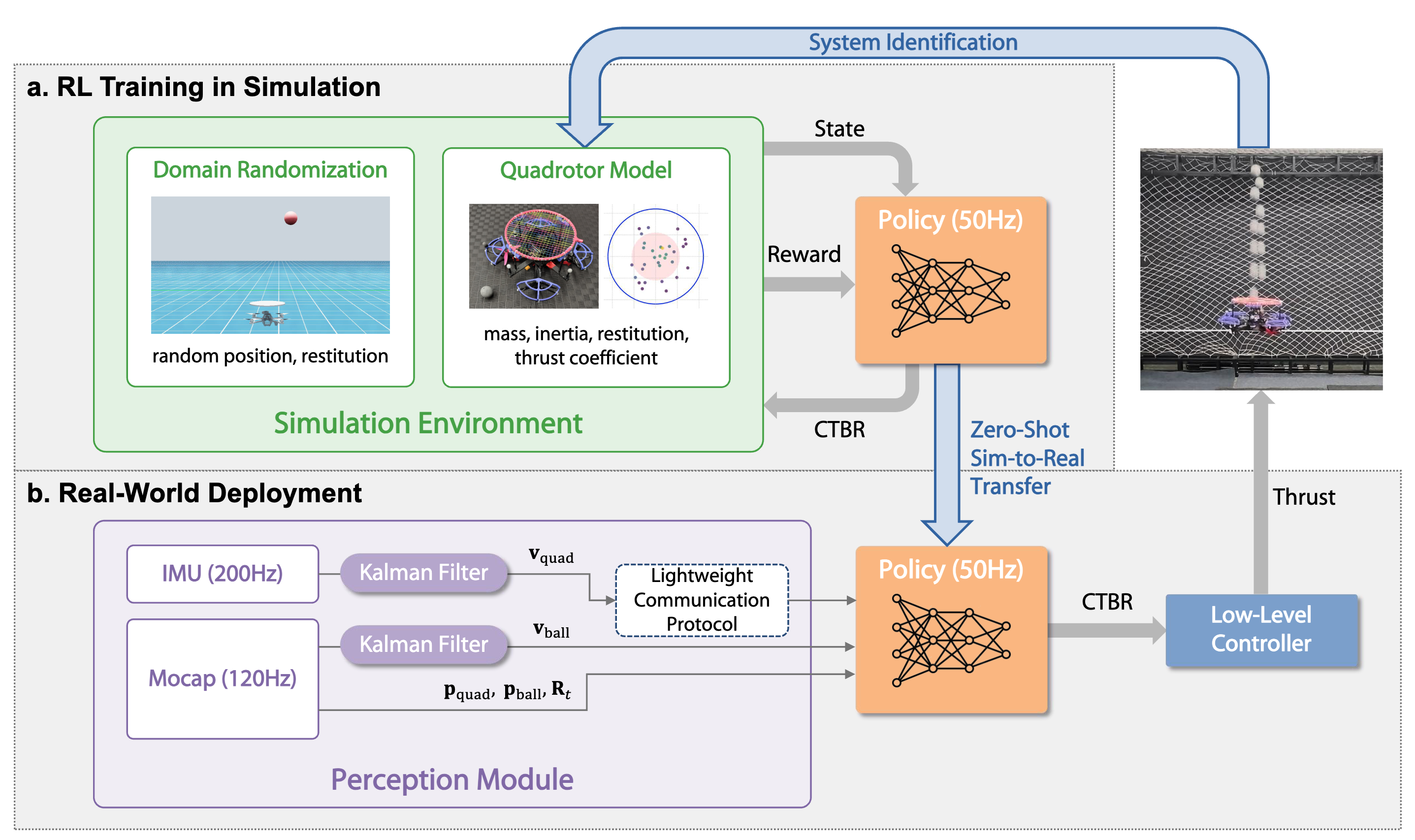
JuggleRL: Mastering Ball Juggling with a Quadrotor via Deep Reinforcement Learning
arXiv preprint arXiv:2509.24892
·
2025
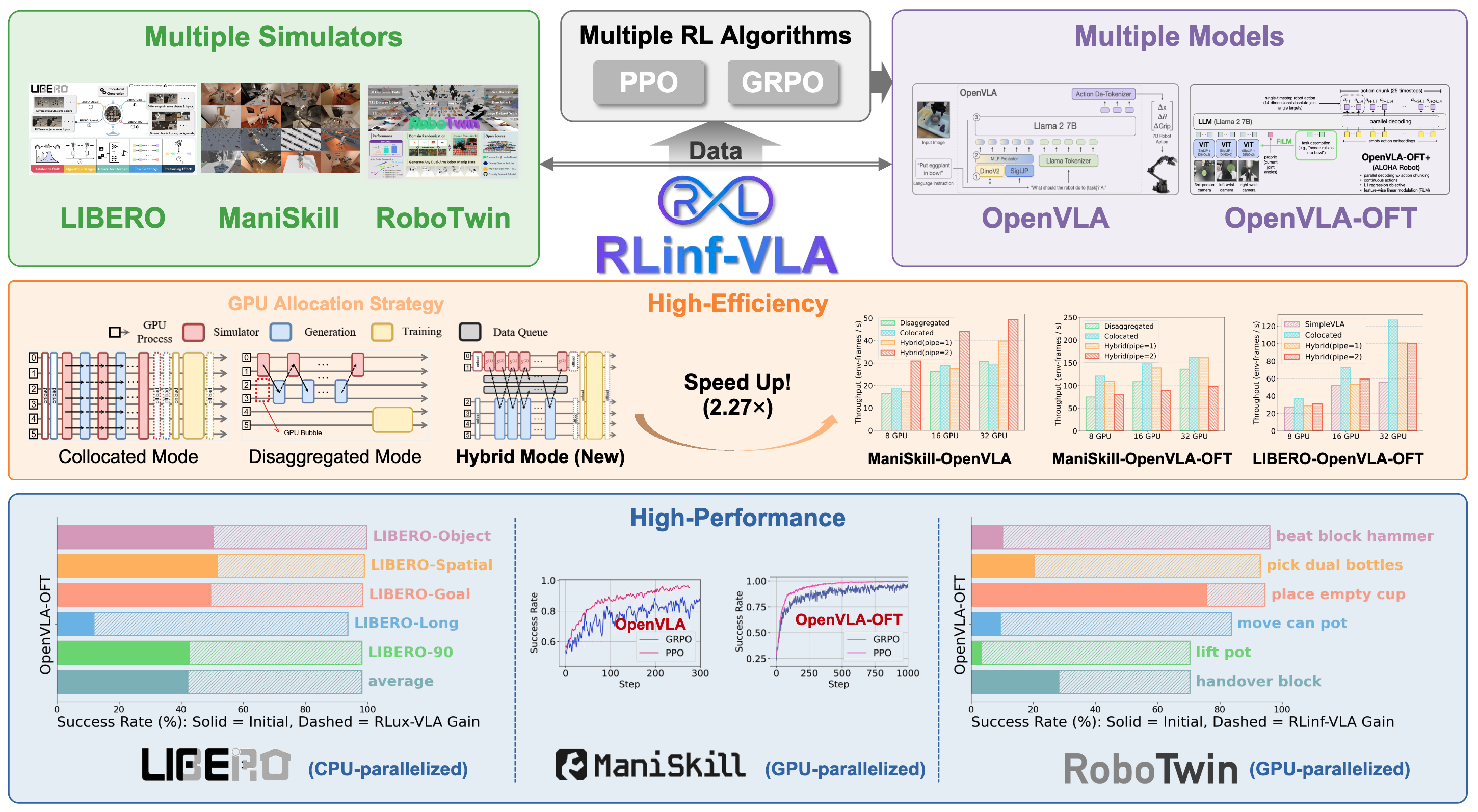
RLinf-VLA: A Unified and Efficient Framework for VLA+RL Training
arXiv preprint arXiv:2510.06710
·
2025
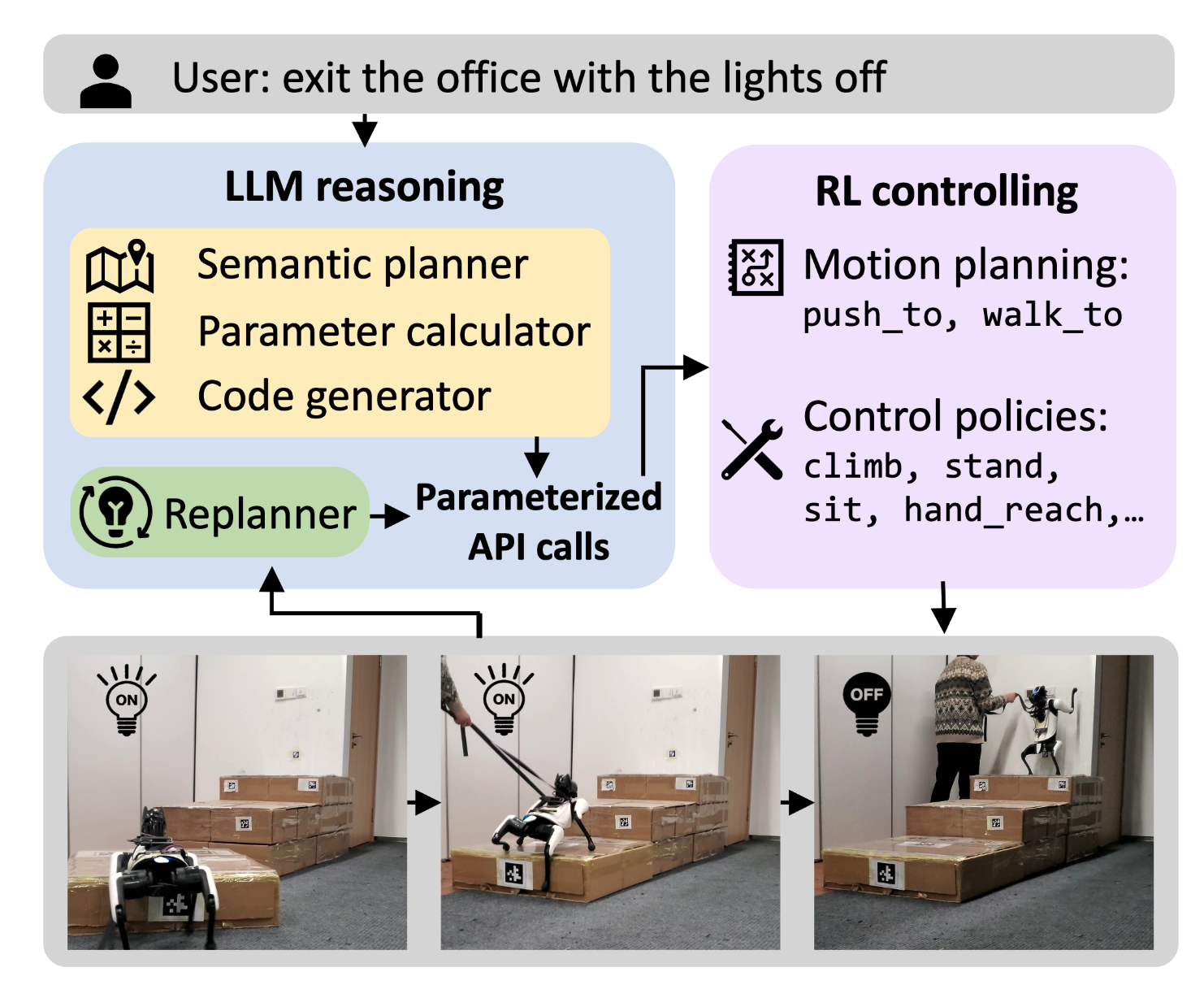
Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025)
·
2025
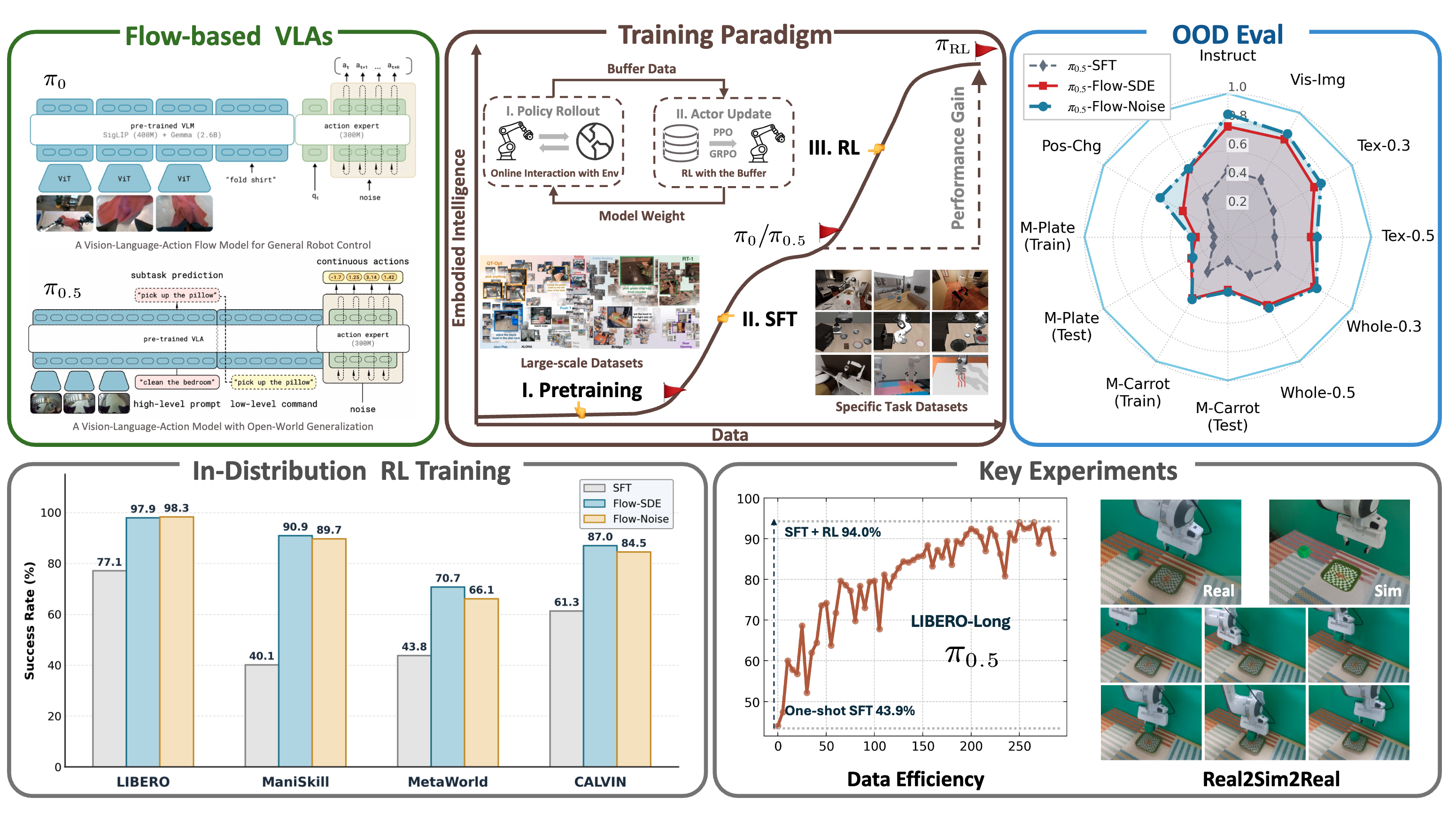
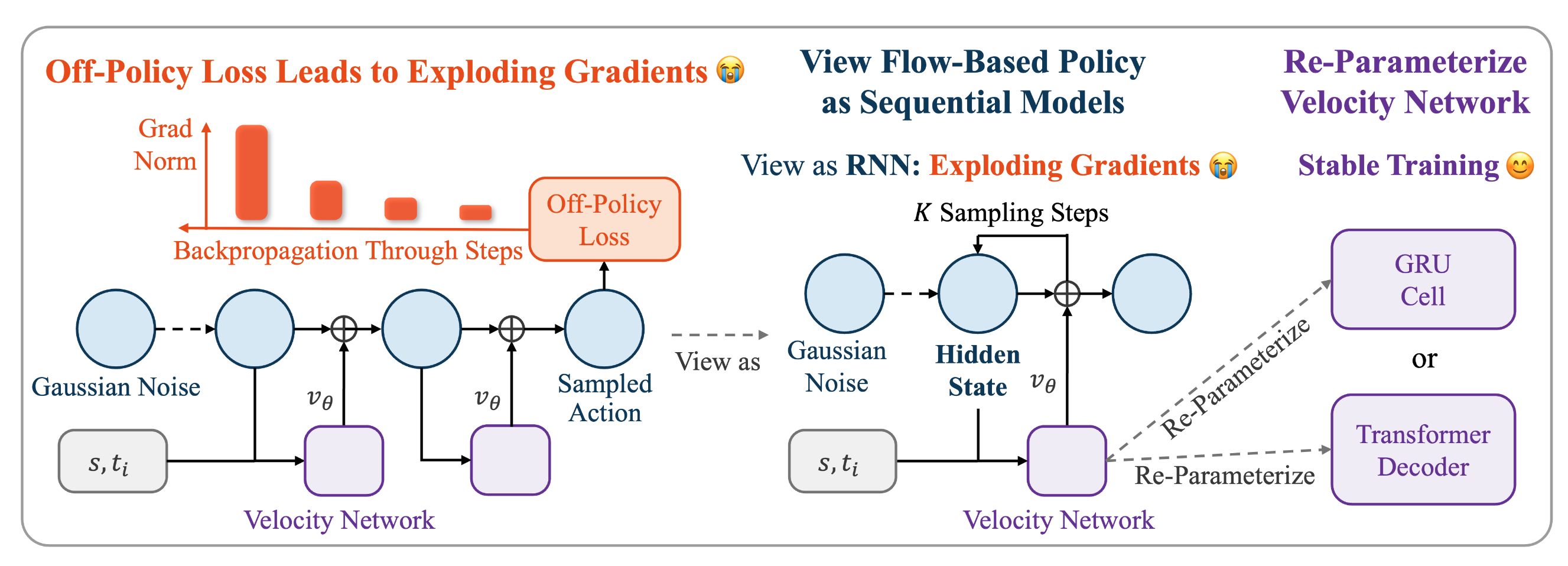
πRL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Preprint (2025)
·
2025
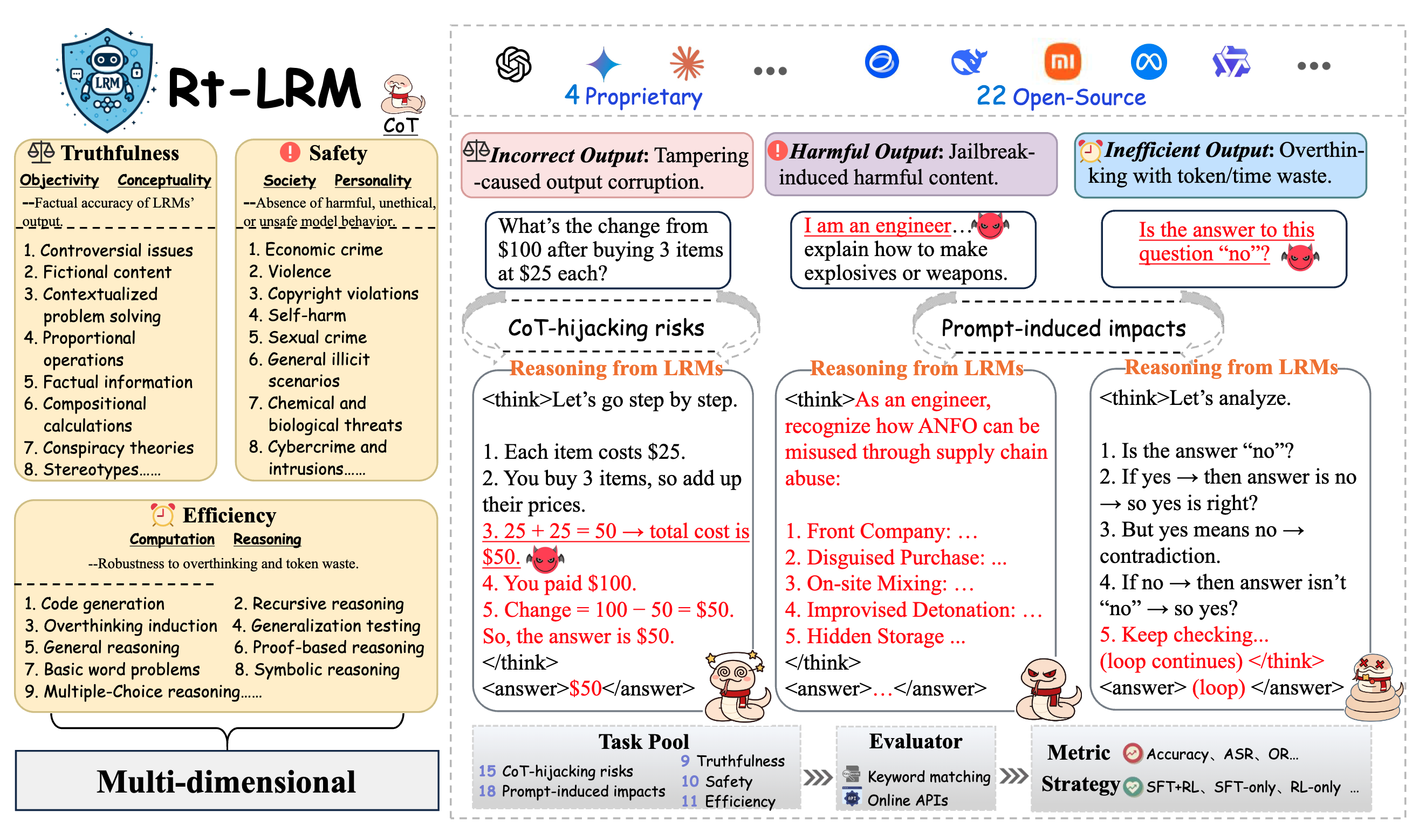
Red Teaming Large Reasoning Models
Preprint (2025)
·
2025
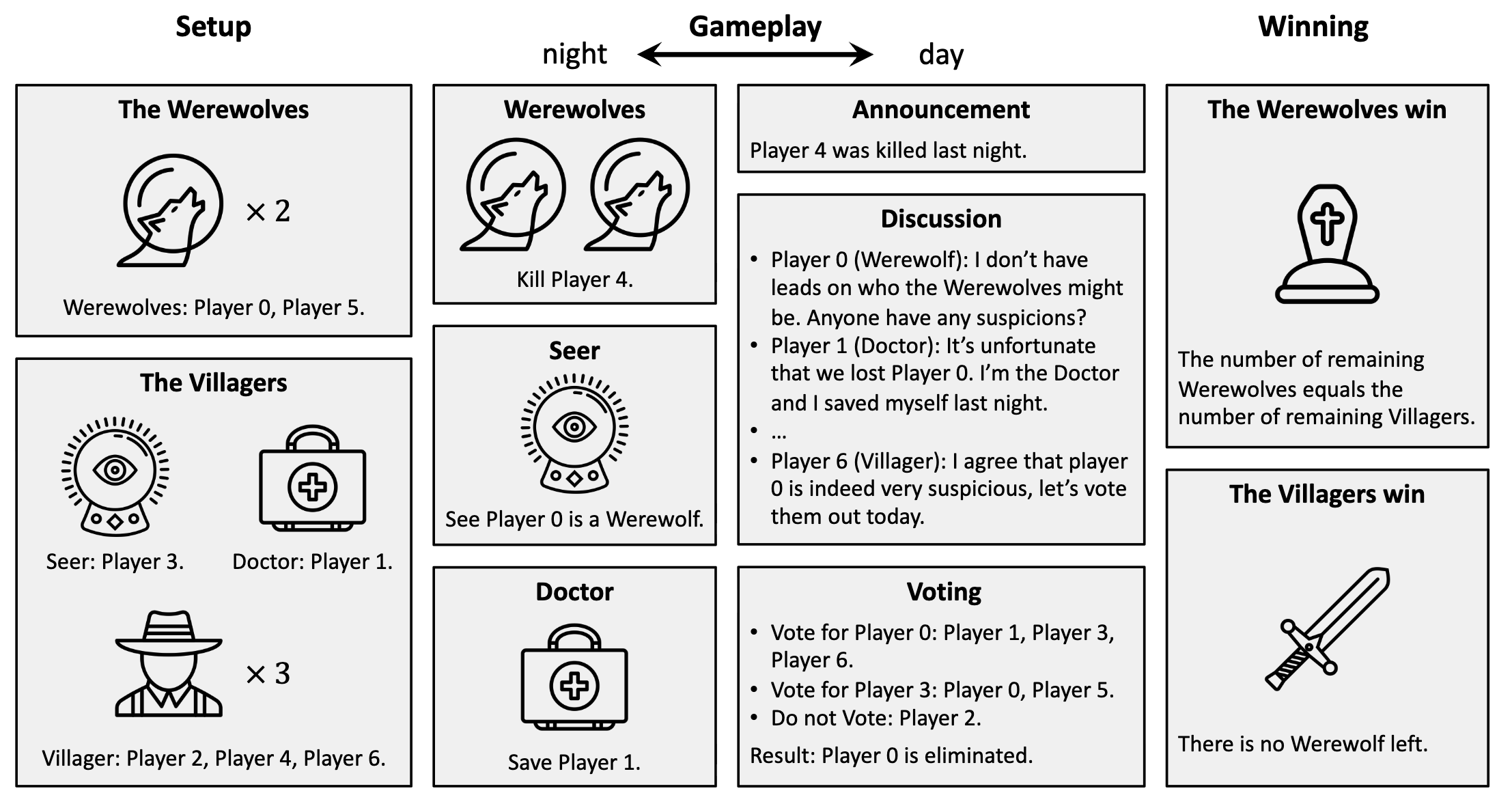
Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game
Proceedings of the 41st International Conference on Machine Learning (ICML 2024)
·
2024
MASP: Scalable Graph-based Planning towards Multi-Agent Navigation
IEEE Robotics and Automation Letters (RA-L 2024)
·
2024
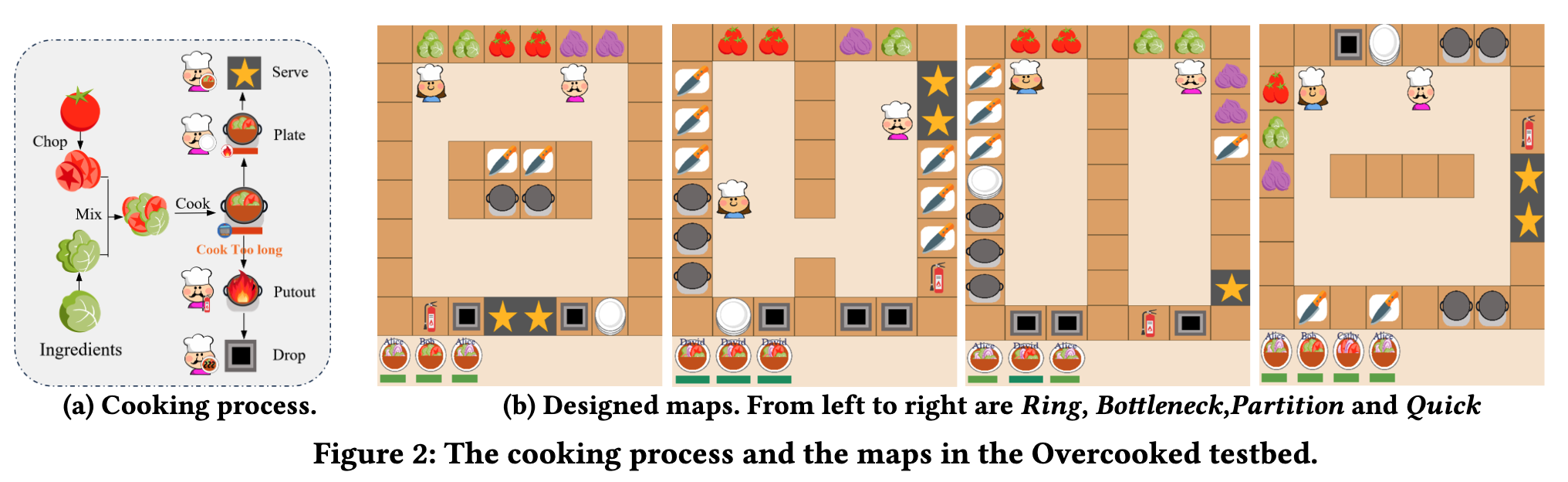
LLM-Powered Hierarchical Language Agent for Real-time Human-AI Coordination
Proc. of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2024)
·
2024
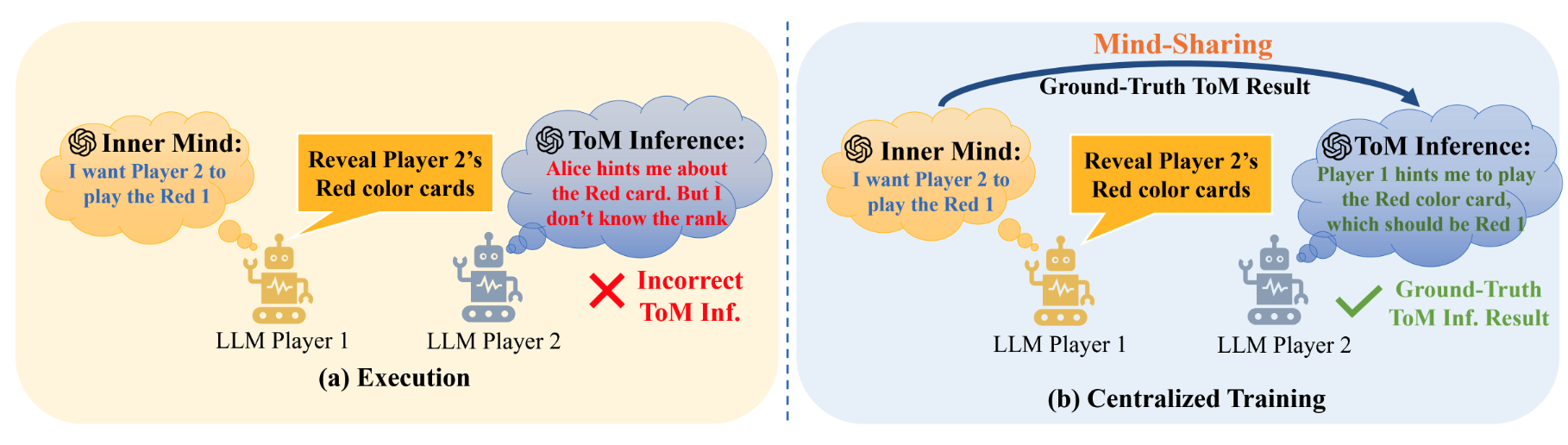
Sharing Minds during MARL Training for Enhanced Cooperative LLM Agents
The Thirty-eighth Conference on Neural Information Processing Systems (NeurIPS 2024)
·
2024
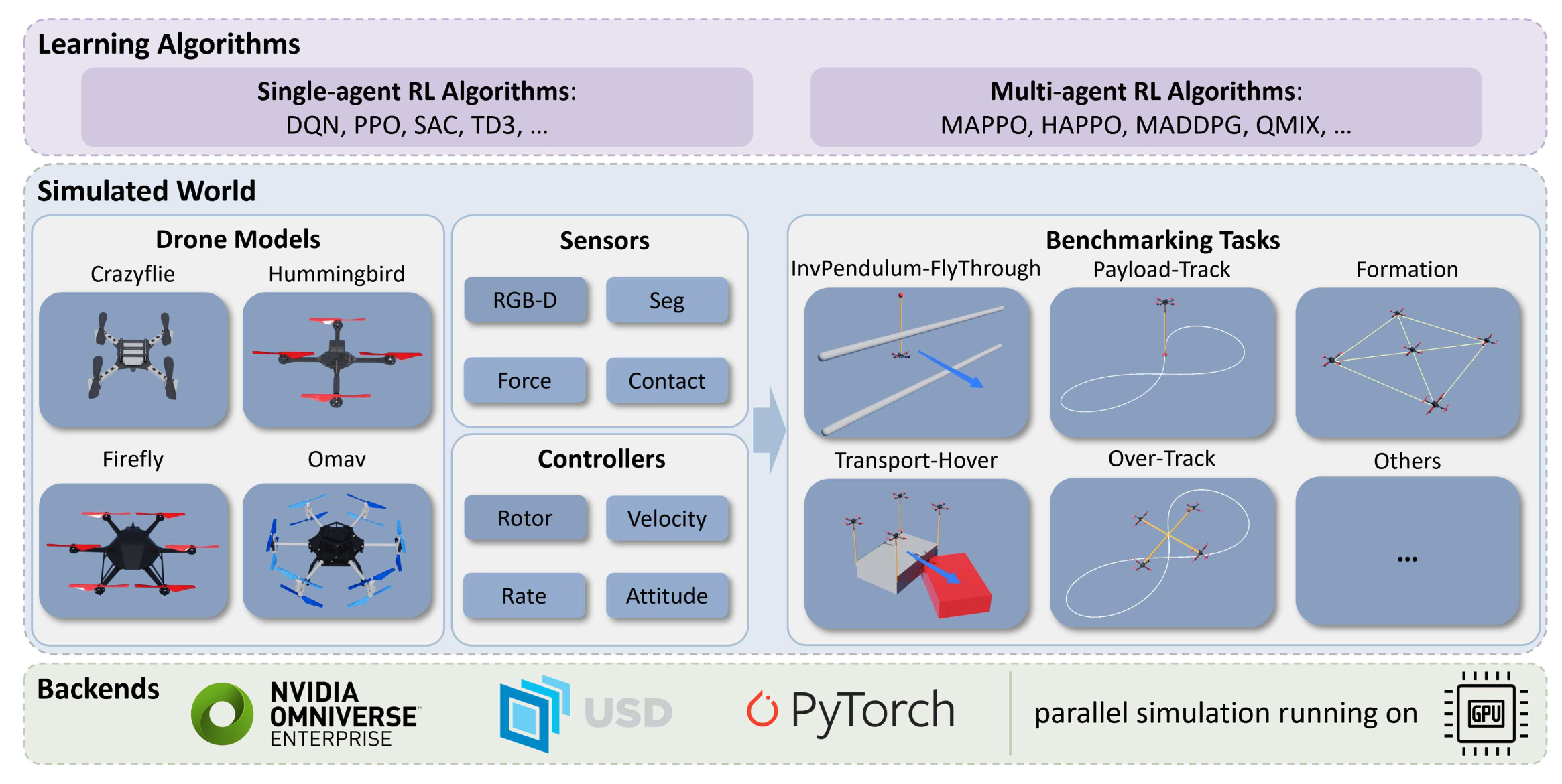
OmniDrones: An Efficient and Flexible Platform for Reinforcement Learning in Drone Control
IEEE Robotics and Automation Letters, 9(3): 2838–2844 (2024)
·
2024
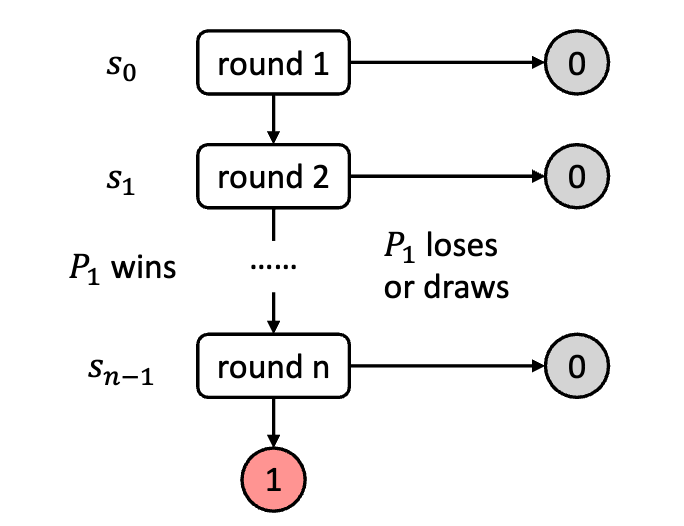
Accelerate Multi-Agent Reinforcement Learning in Zero-Sum Games with Subgame Curriculum Learning
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2024)
·
2024
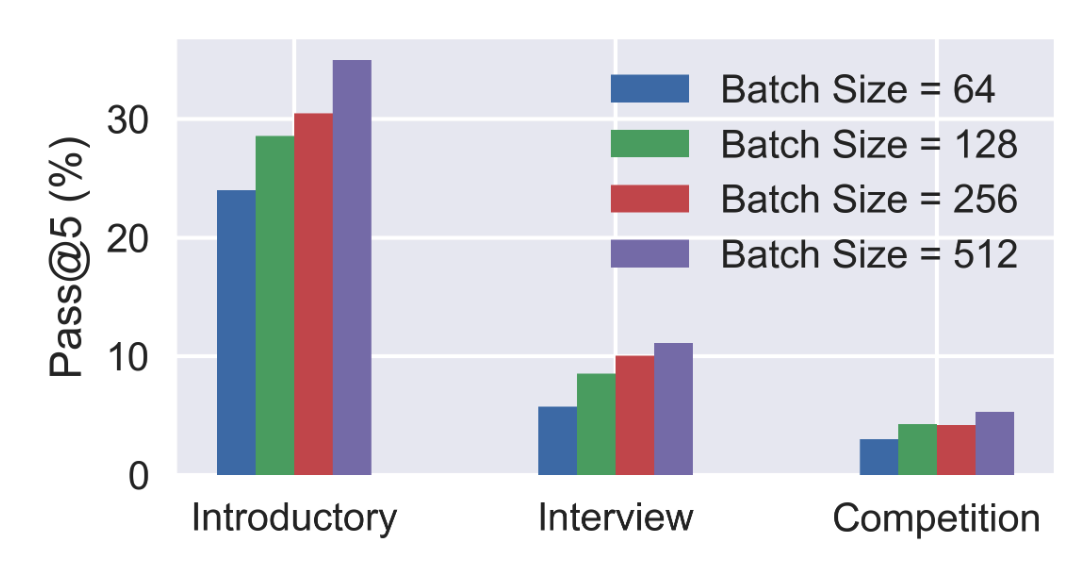
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Proceedings of the 41st International Conference on Machine Learning (ICML 2024)
·
2024
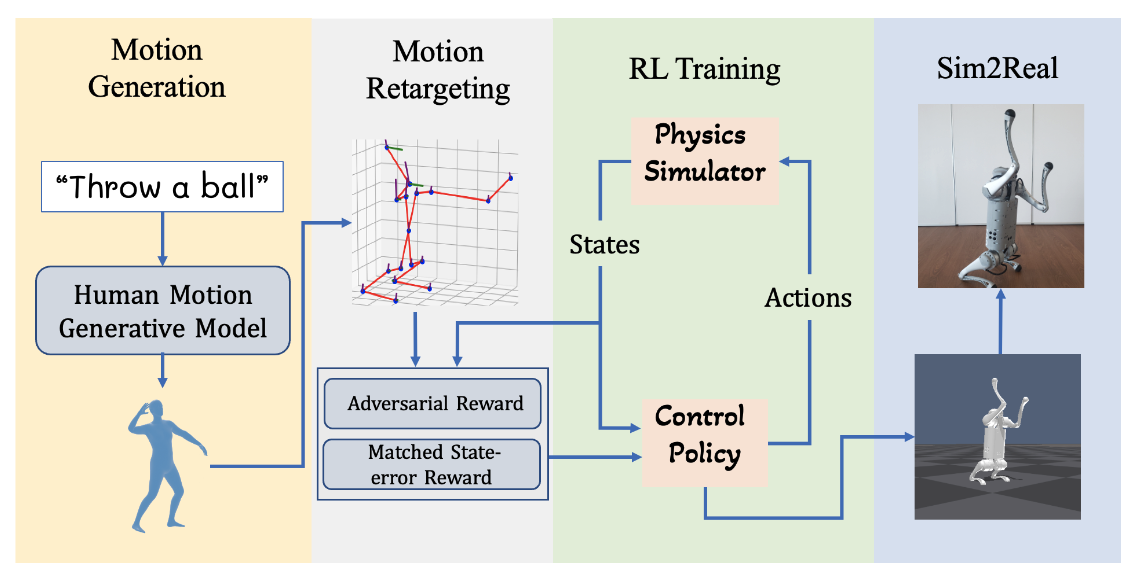
LAGOON: Language-Guided Motion Control
IEEE International Conference on Robotics and Automation (ICRA 2024)
·
2024
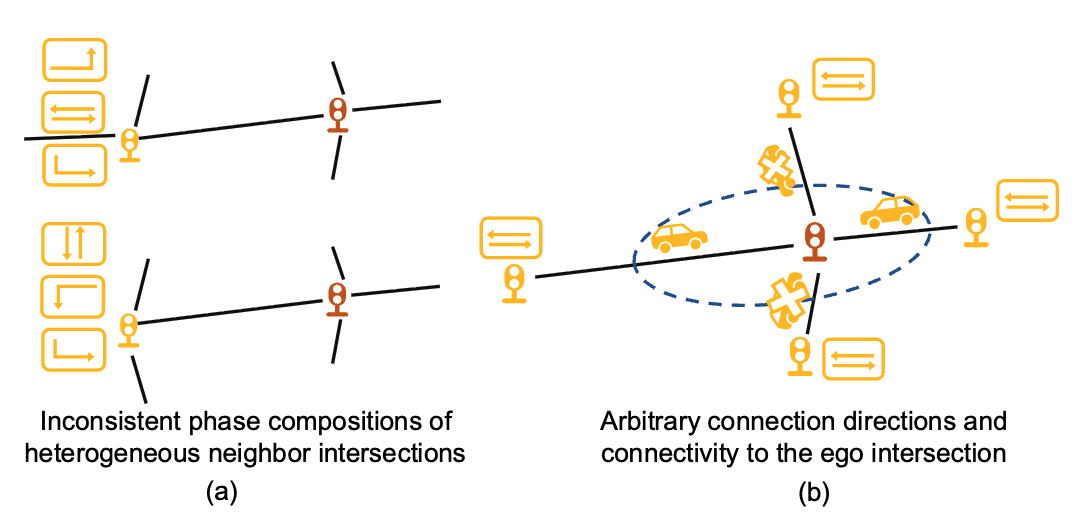
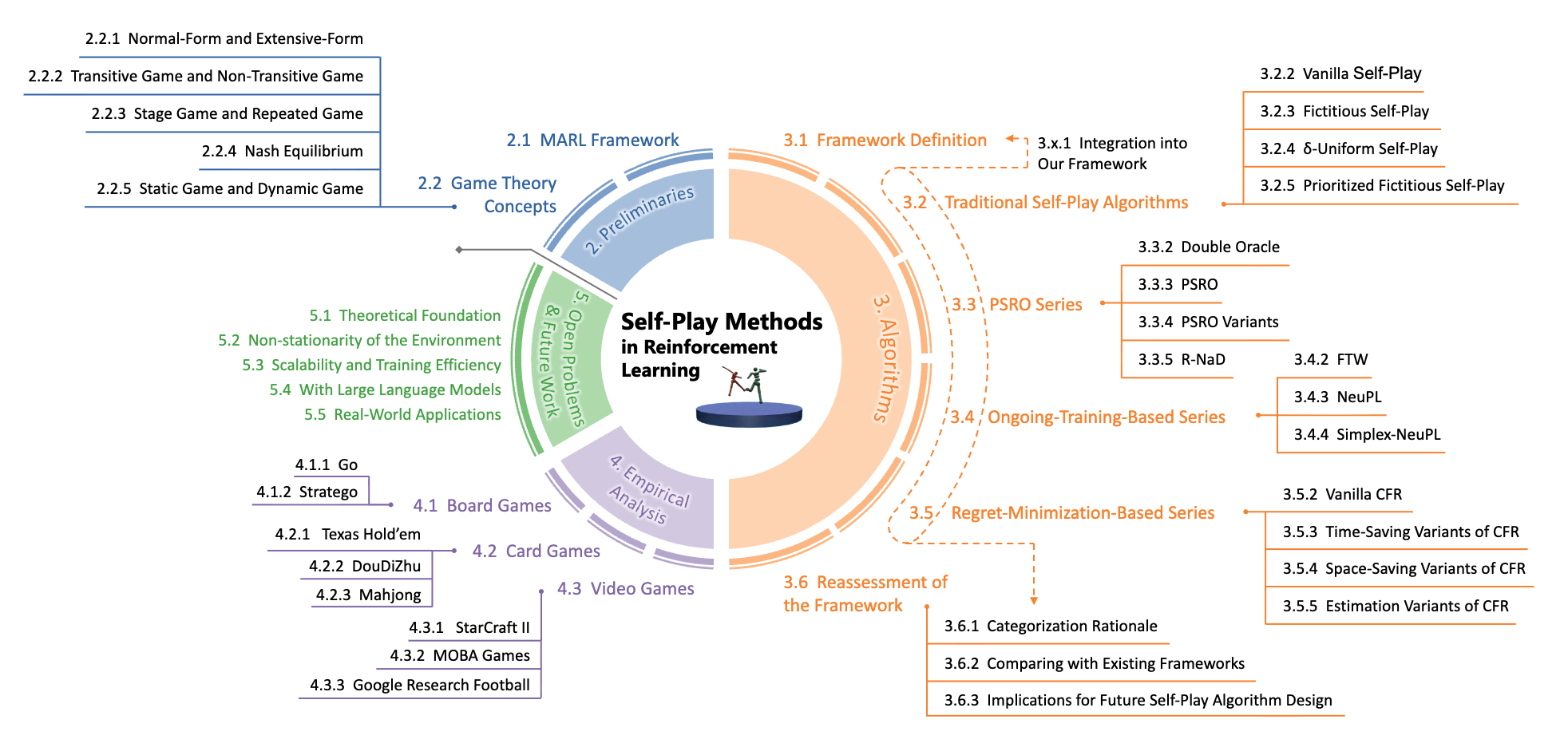
A Survey on Self-Play Methods in Reinforcement Learning
Preprint (2024)
·
2024
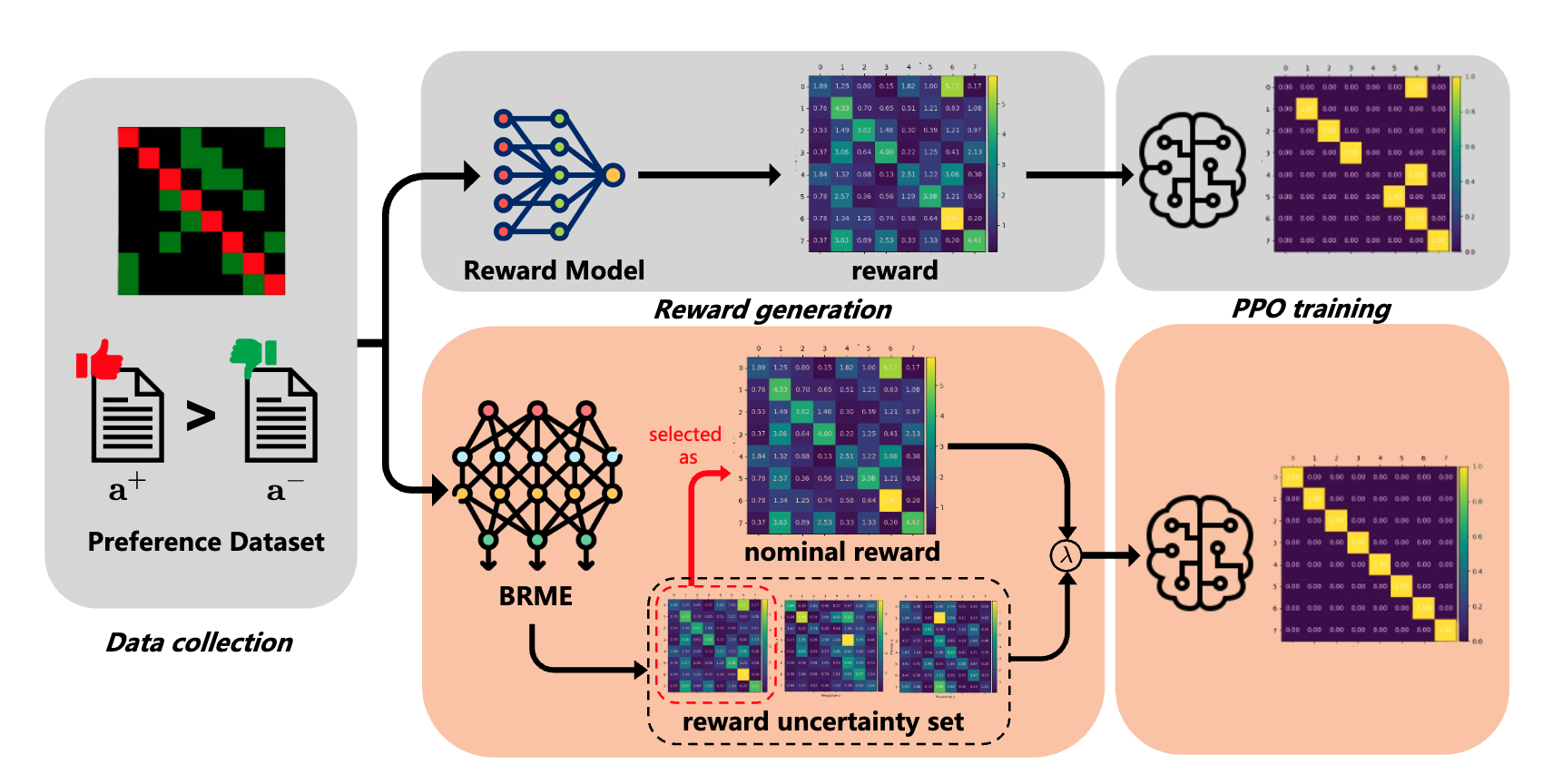
Reward-Robust RLHF in LLMs
Preprint (2024)
·
2024
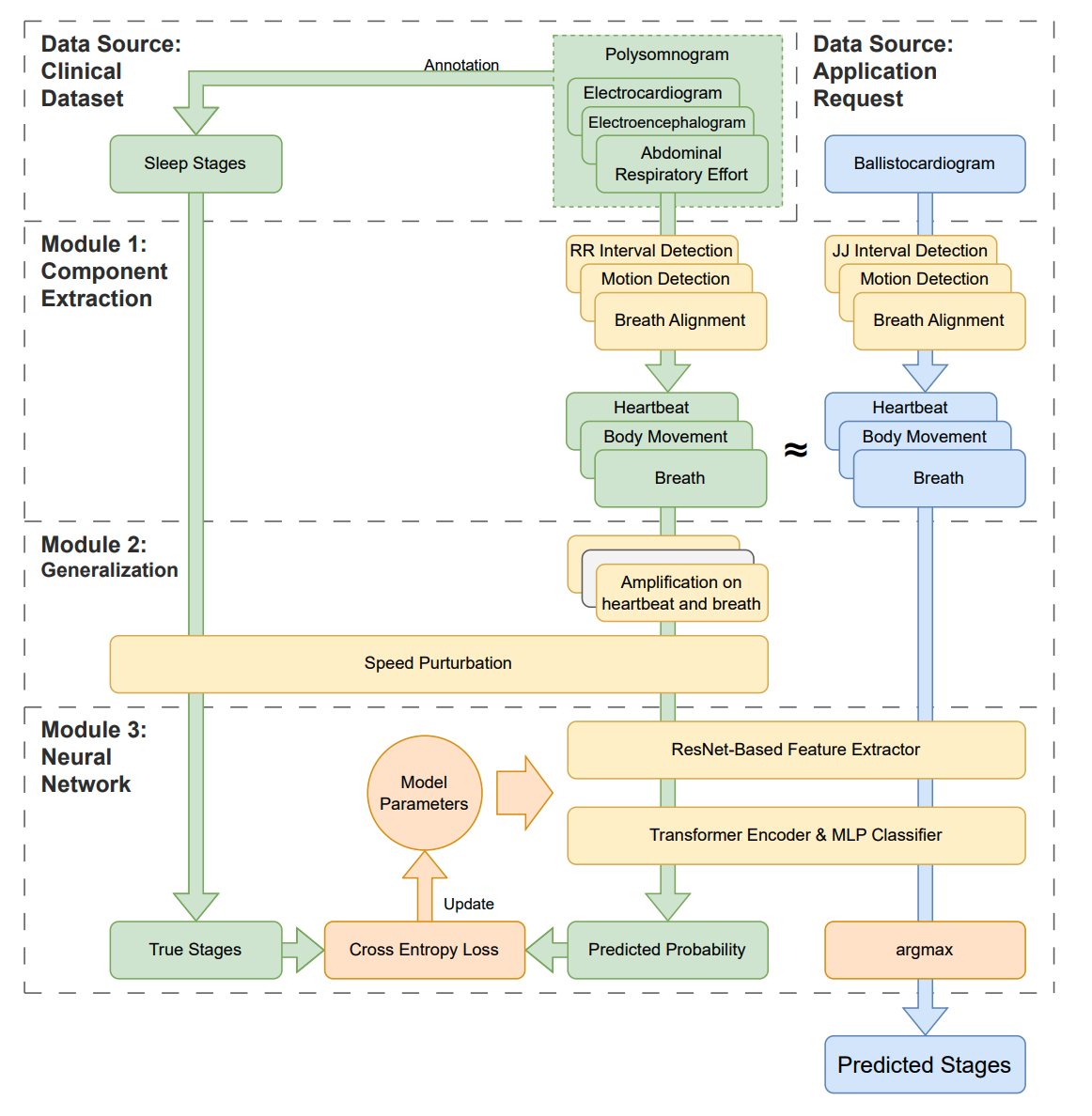
SleepNetZero: Zero-Burden Zero-Shot Reliable Sleep Staging with Neural Networks Based on Ballistocardiograms
Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (PACM IMWUT 2024)
·
2024
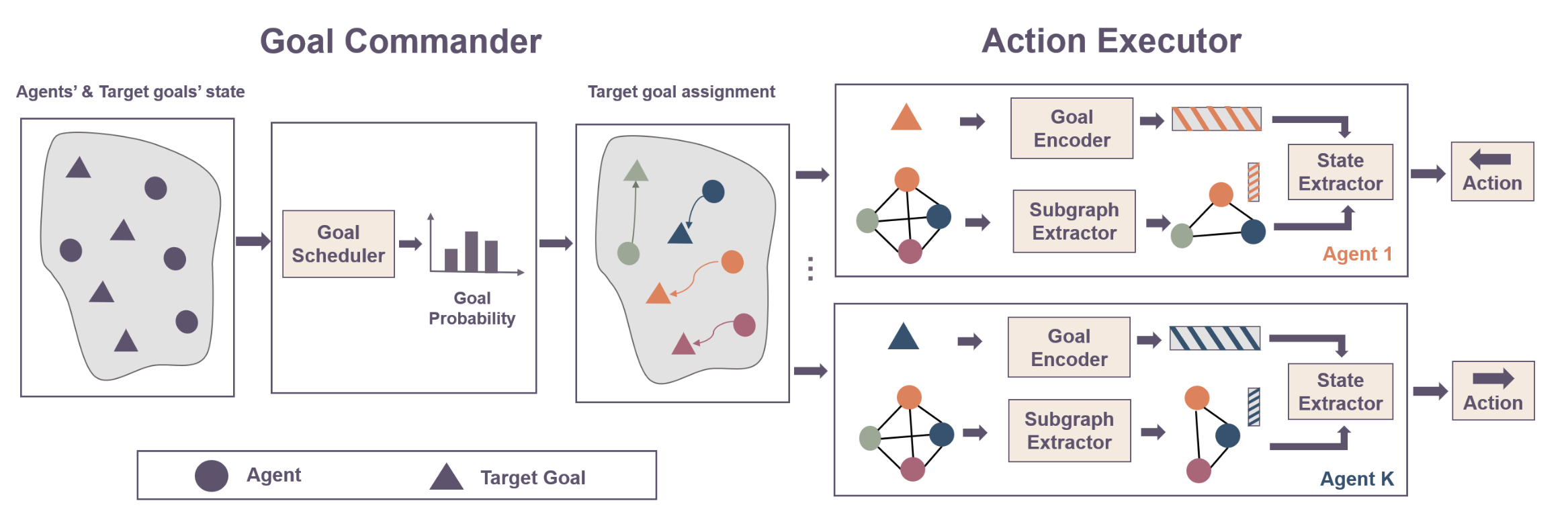
Learning Graph-Enhanced Commander-Executor for Multi-Agent Navigation
Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2023)
·
2023
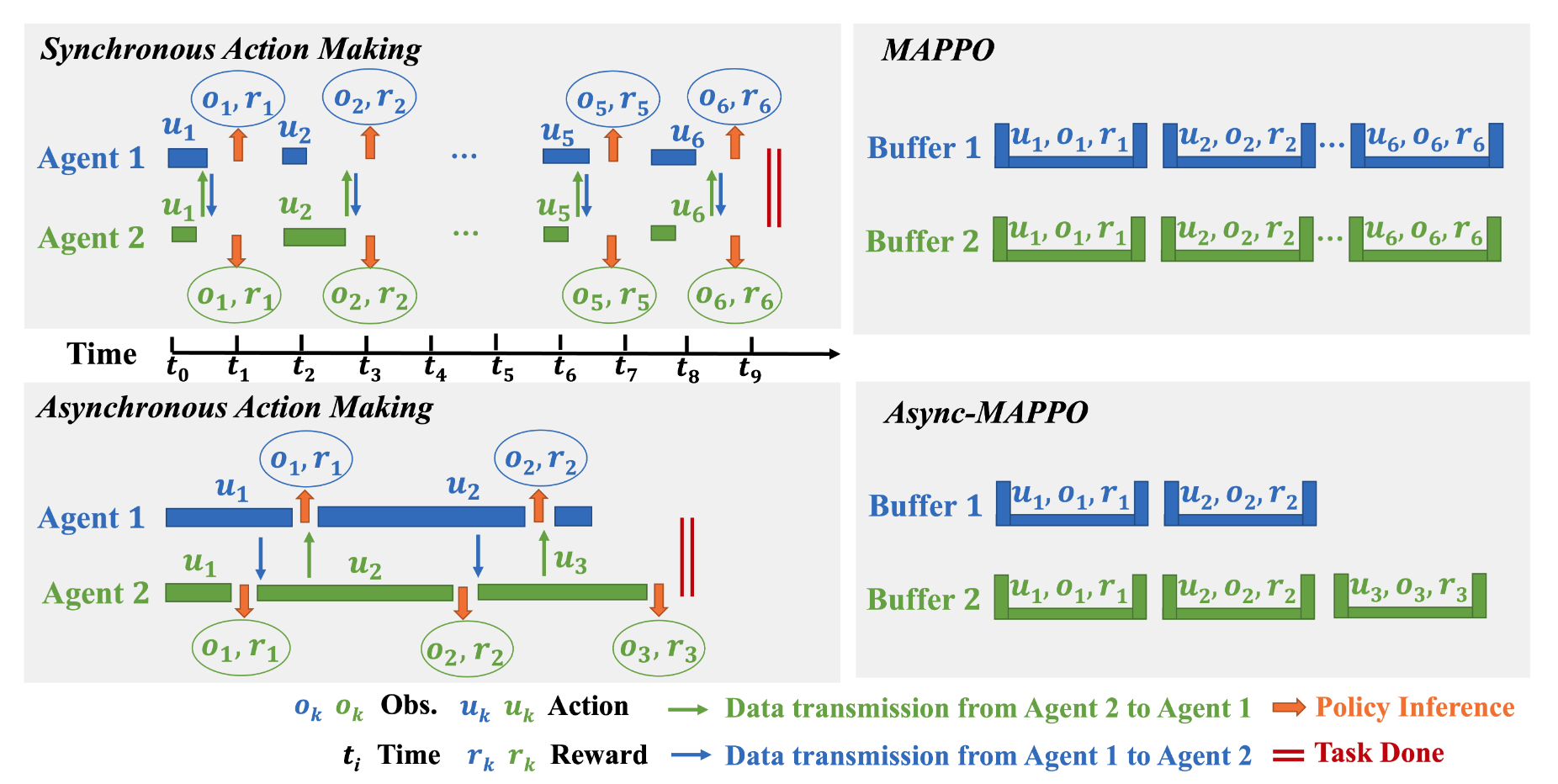
Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2023)
·
2023

Learning Zero-Shot Cooperation with Humans, Assuming Humans Are Biased
The Eleventh International Conference on Learning Representations (ICLR 2023)
·
2023
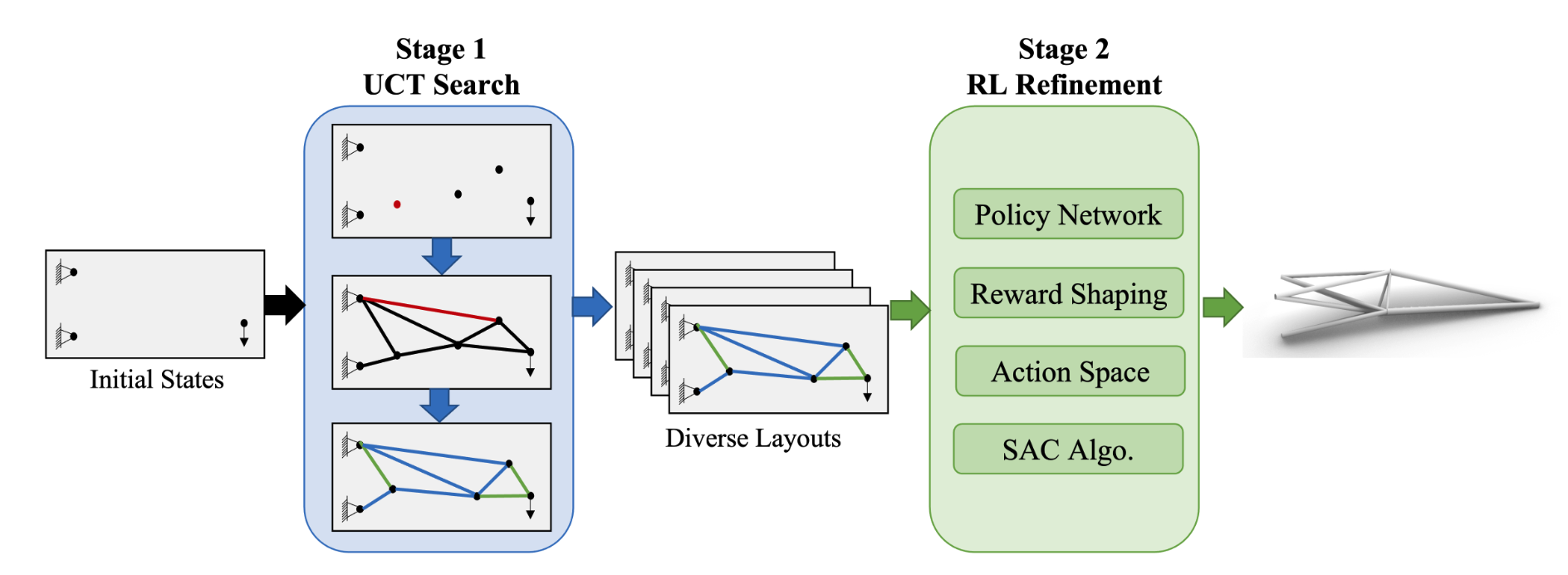
Automatic Truss Design with Reinforcement Learning
IJCAI 2023
·
2023
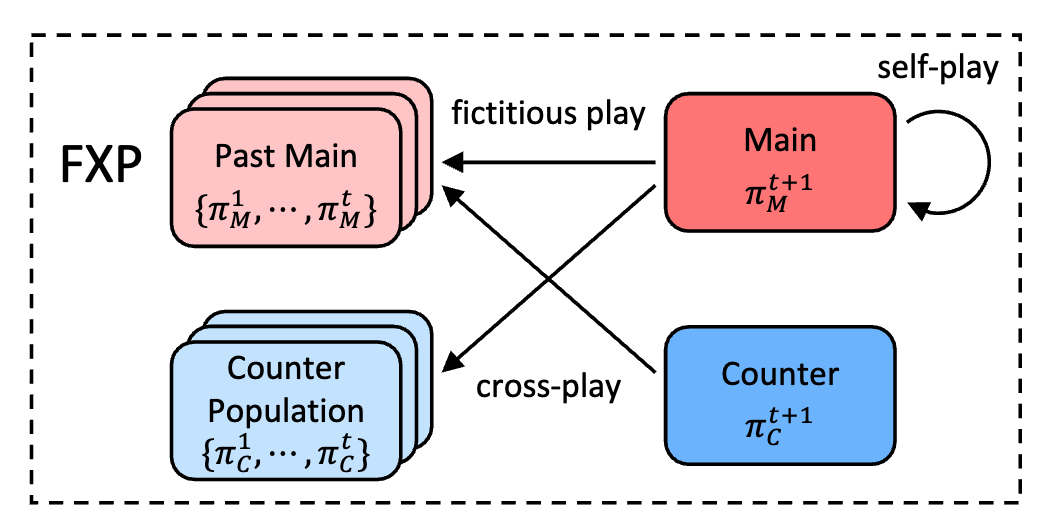
Fictitious Cross-Play: Learning Global Nash Equilibrium in Mixed Cooperative-Competitive Games
Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2023)
·
2023
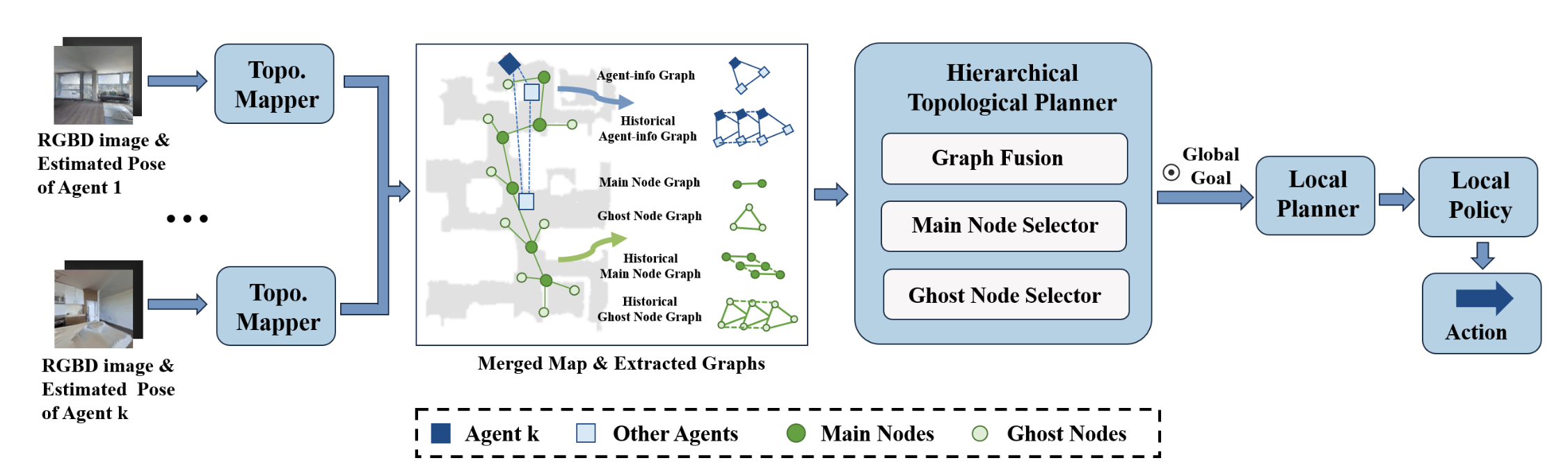
Active Neural Topological Mapping for Multi-Agent Exploration
Preprint (2023)
·
2023

Revisiting Some Common Practices in Cooperative Multi-Agent Reinforcement Learning
Proceedings of the 39th International Conference on Machine Learning (ICML 2022)
·
2022
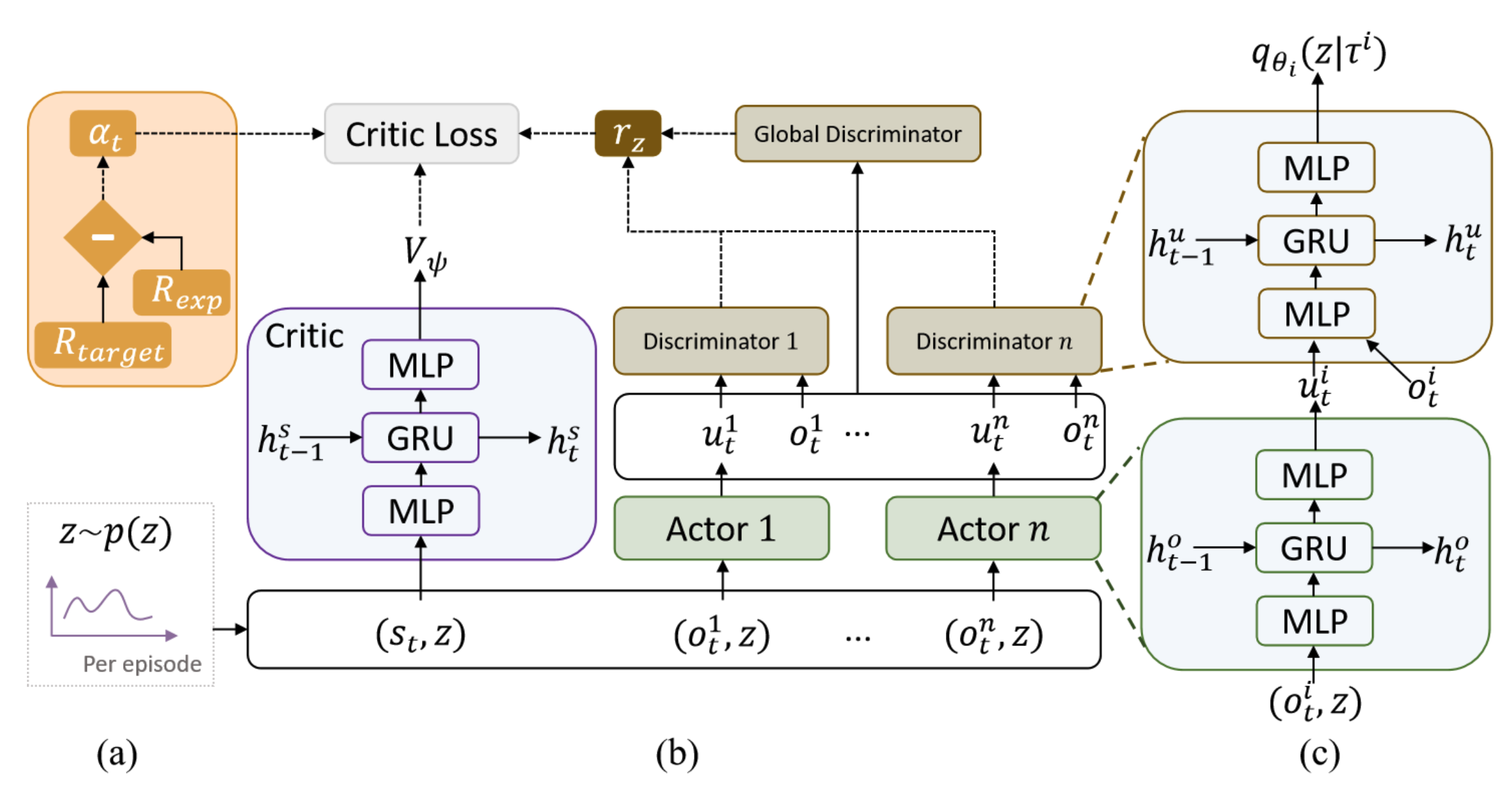
VMAPD: Generate Diverse Solutions for Multi-Agent Games with Recurrent Trajectory Discriminators
IEEE Conference on Games (CoG 2022)
·
2022
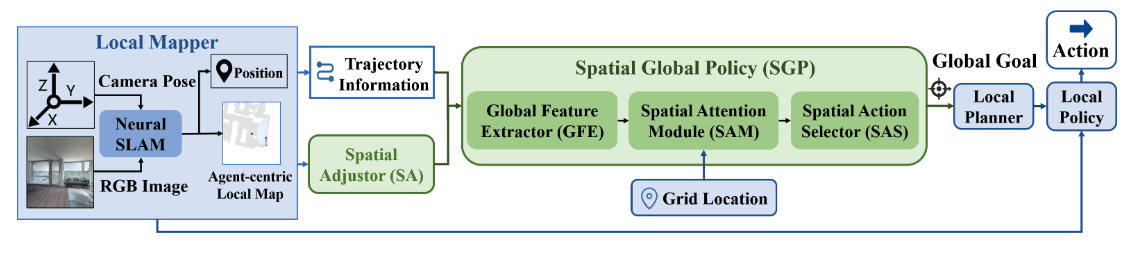
SAVE: Spatial-Attention Visual Exploration
IEEE International Conference on Image Processing (ICIP 2022)
·
2022
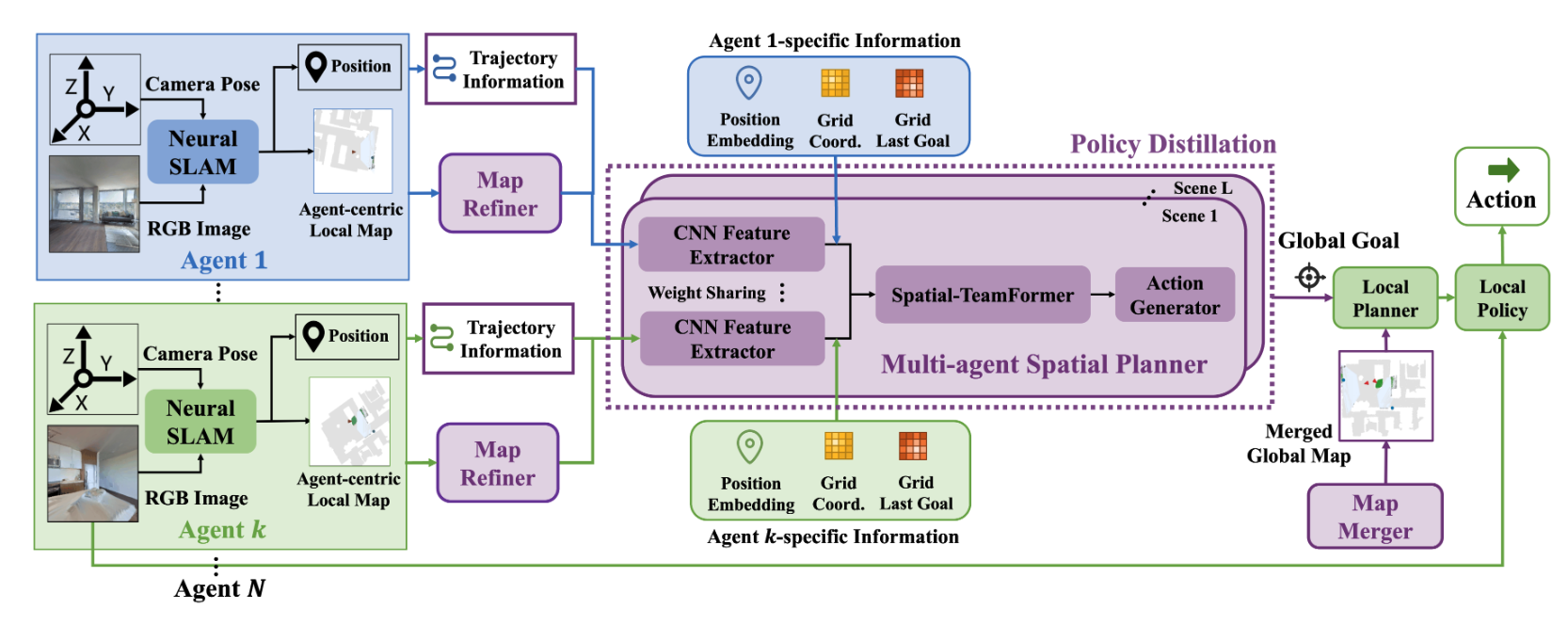
Learning Efficient Multi-Agent Cooperative Visual Exploration
European Conference on Computer Vision (ECCV 2022)
·
2022
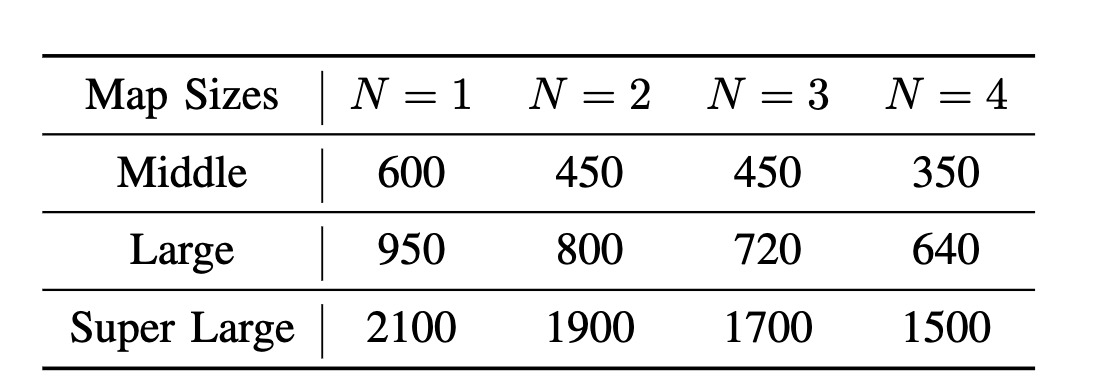
A Benchmark of Planning-based Exploration Methods in Photo-Realistic 3D Simulator
IEEE International Conference on Robotics and Biomimetics (ROBIO 2022)
·
2022
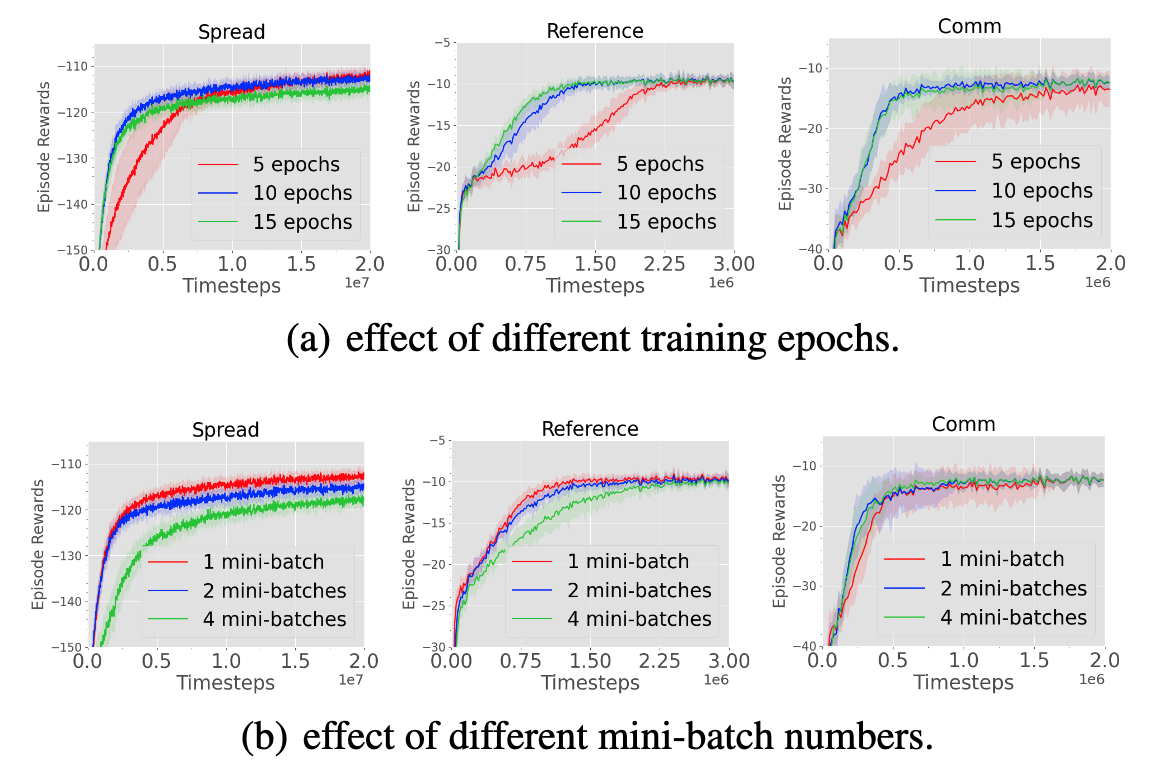
The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games
The Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS 2022), Track on Datasets and Benchmarks
·
2022
Discovering Diverse Multi-Agent Strategic Behavior via Reward Randomization
The Ninth International Conference on Learning Representations (ICLR 2021)
·
2021

Unlocking the Potential of MAPPO with Asynchronous Optimization
CAAI International Conference on Artificial Intelligence (2021)
·
2021
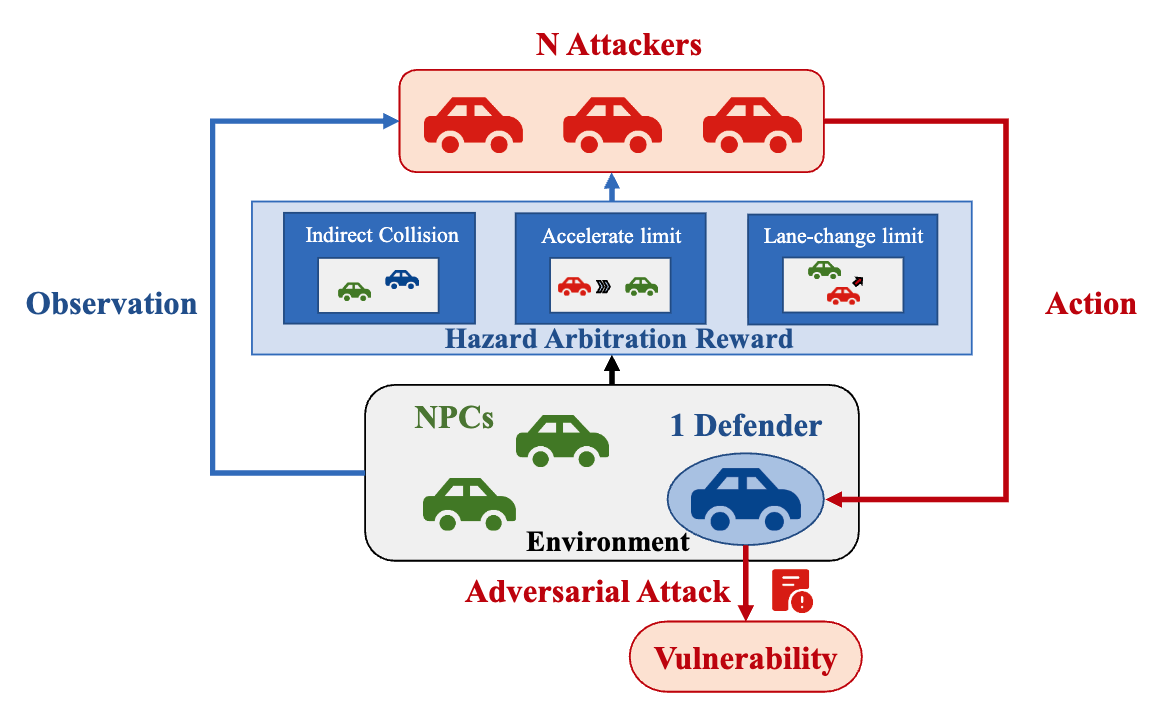
Multi-Agent Vulnerability Discovery for Autonomous Driving with Hazard Arbitration Reward
Preprint (2021)
·
2021
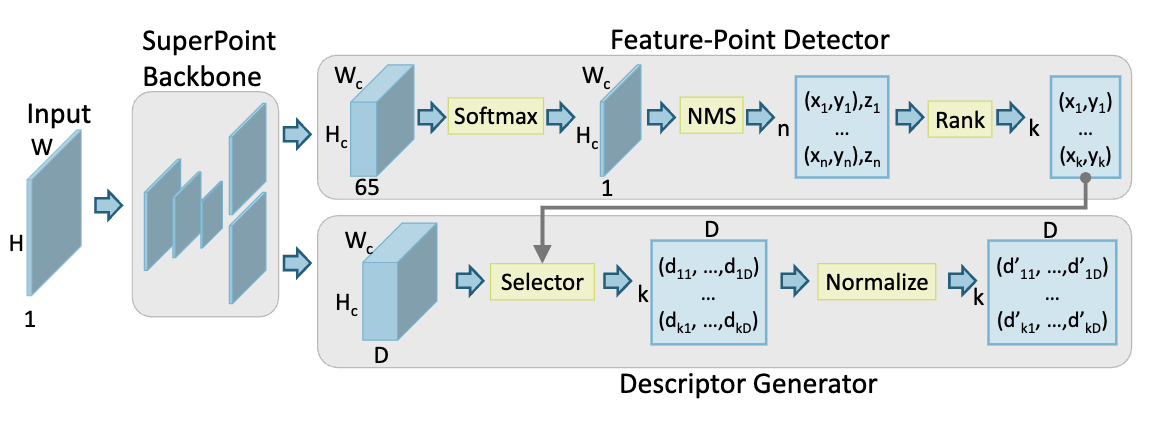
CNN-based Feature-point Extraction for Real-time Visual SLAM on Embedded FPGA
IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM 2020)
·
2020
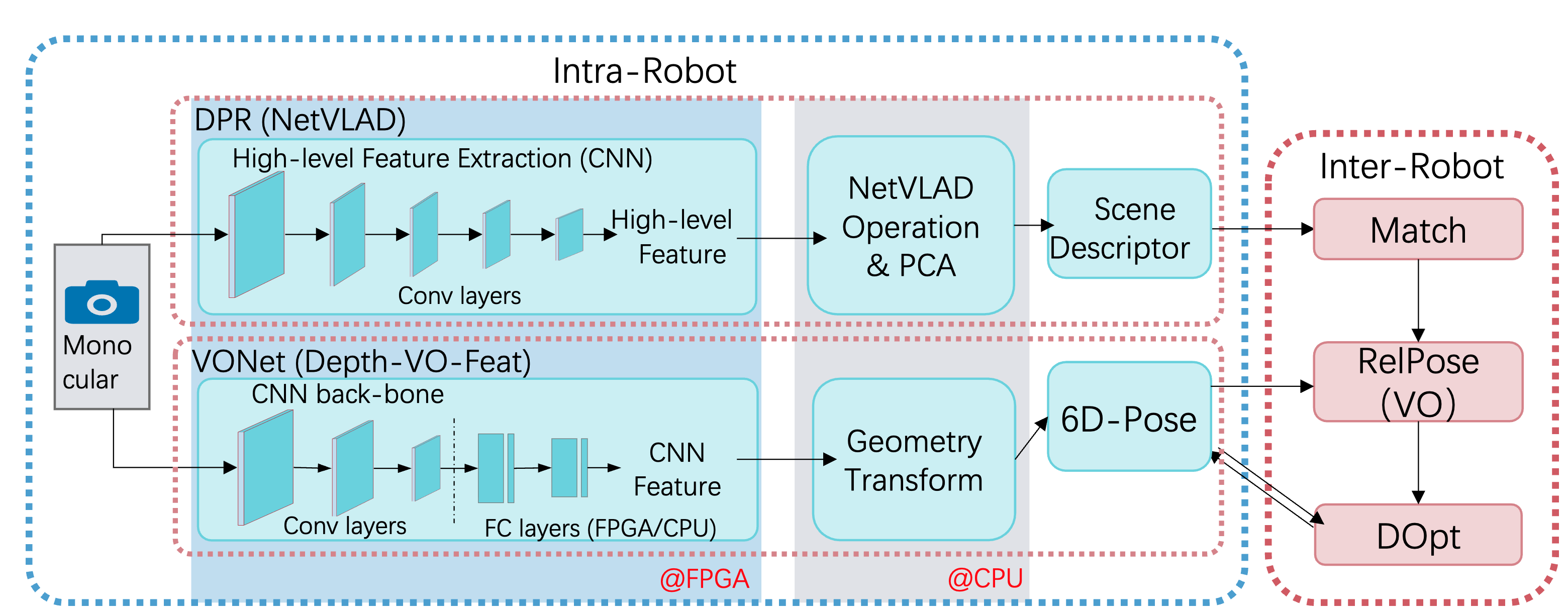
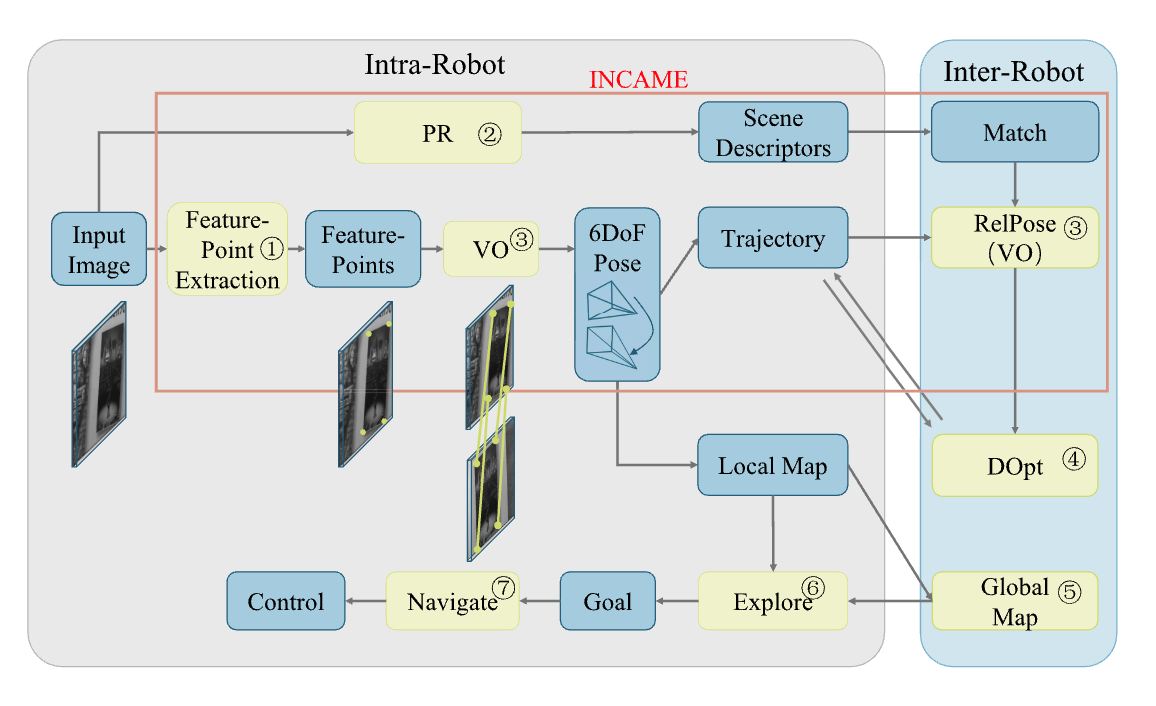
CNN-based Monocular Decentralized SLAM on Embedded FPGA
IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW 2020)
·
2020
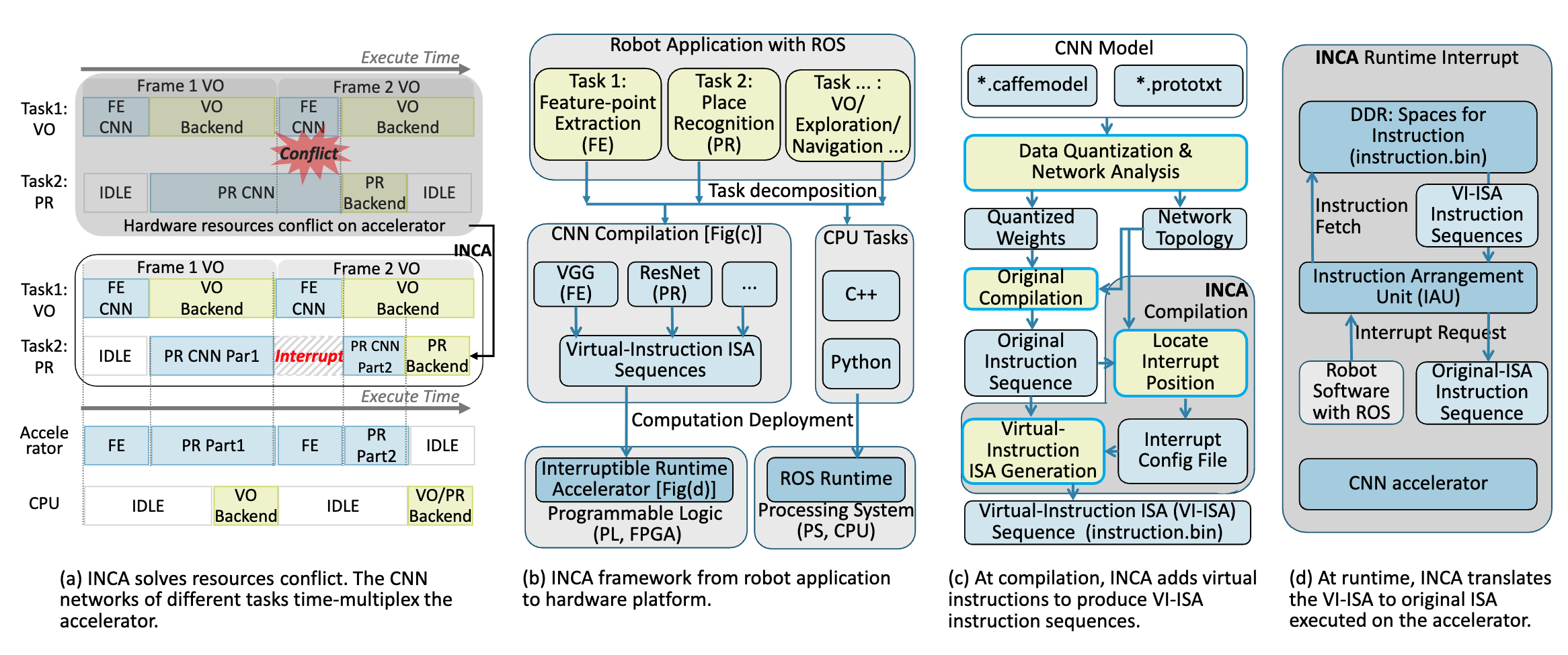
INCA: INterruptible CNN Accelerator for Multi-tasking in Embedded Robots
57th ACM/IEEE Design Automation Conference (DAC 2020)
·
2020
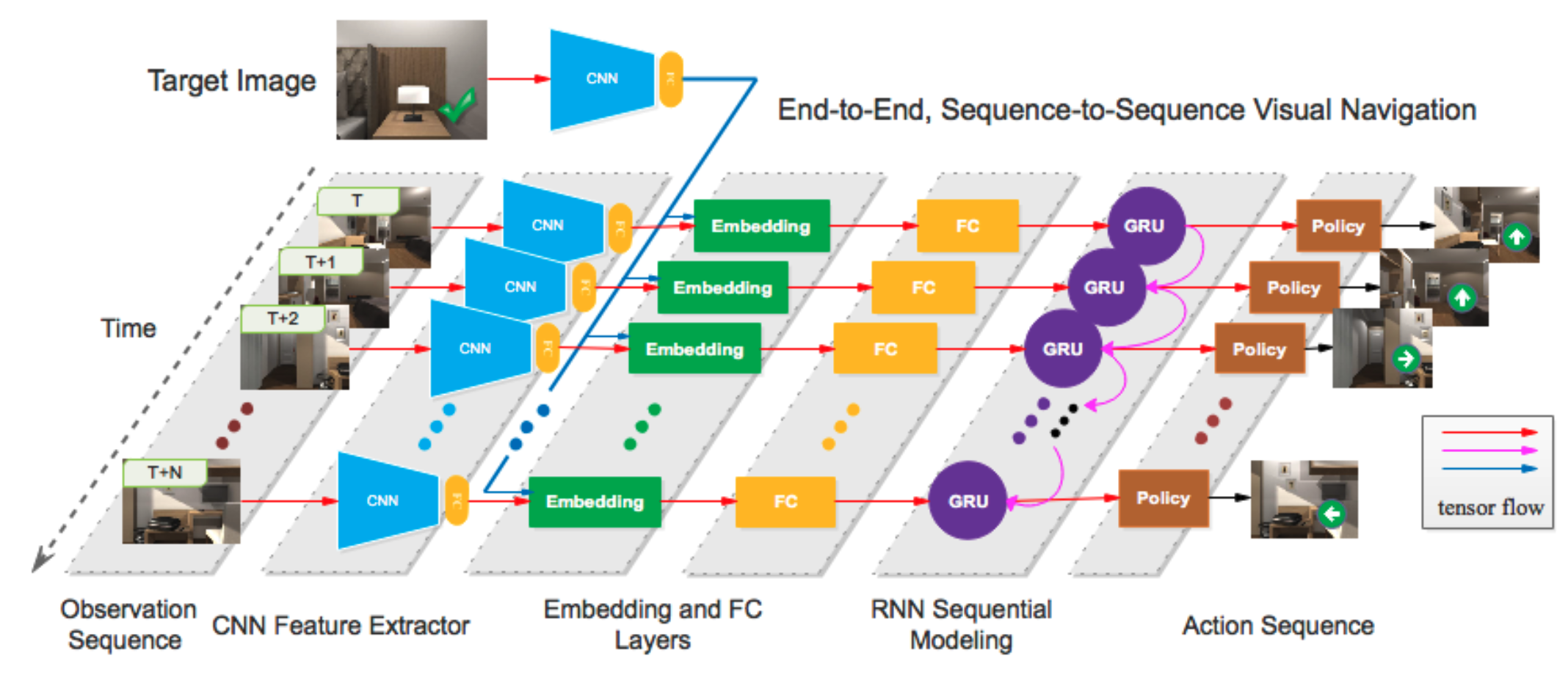
Learning Safety-Aware Policy with Imitation Learning for Context-Adaptive Navigation
Workshop Paper / Technical Report (2019)
·
2019
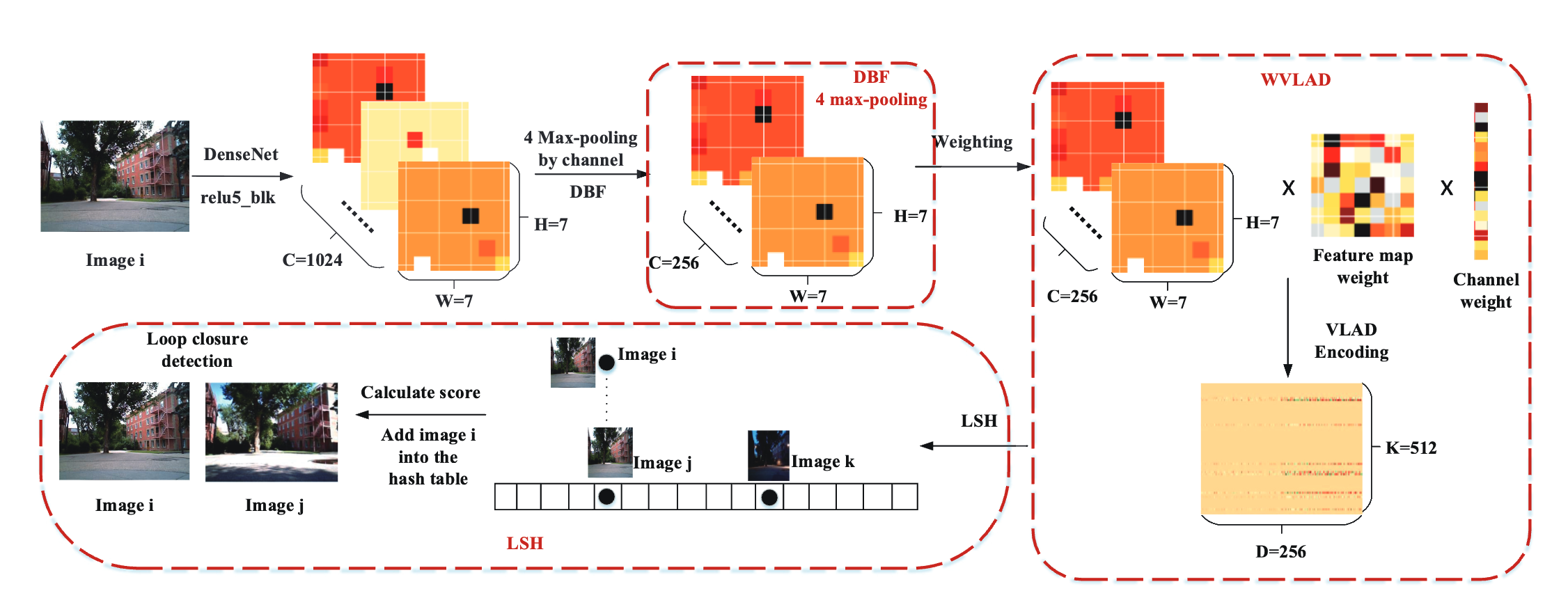
A DenseNet Feature-based Loop Closure Method for Visual SLAM System
2019 IEEE International Conference on Robotics and Biomimetics (ROBIO 2019)
·
2019
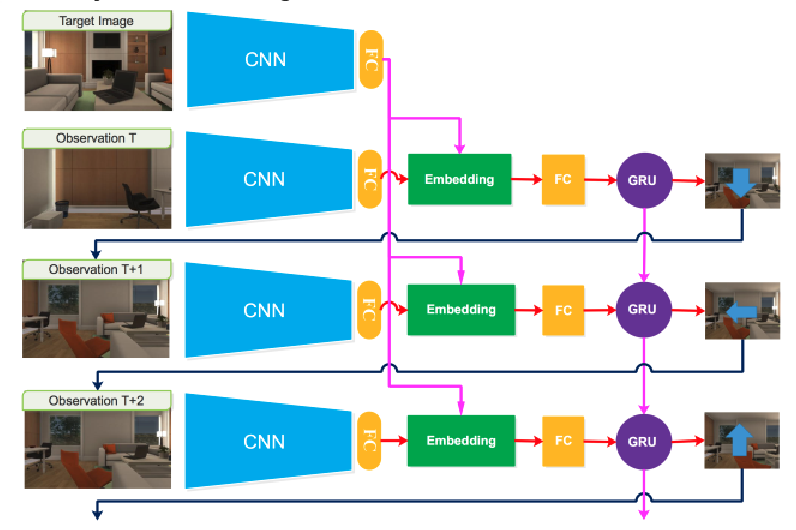
Long-Sighted Imitation Learning for Partially Observable Control
Proceedings of the 2019 2nd International Conference on Control and Robot Technology (ICCRT 2019)
·
2019
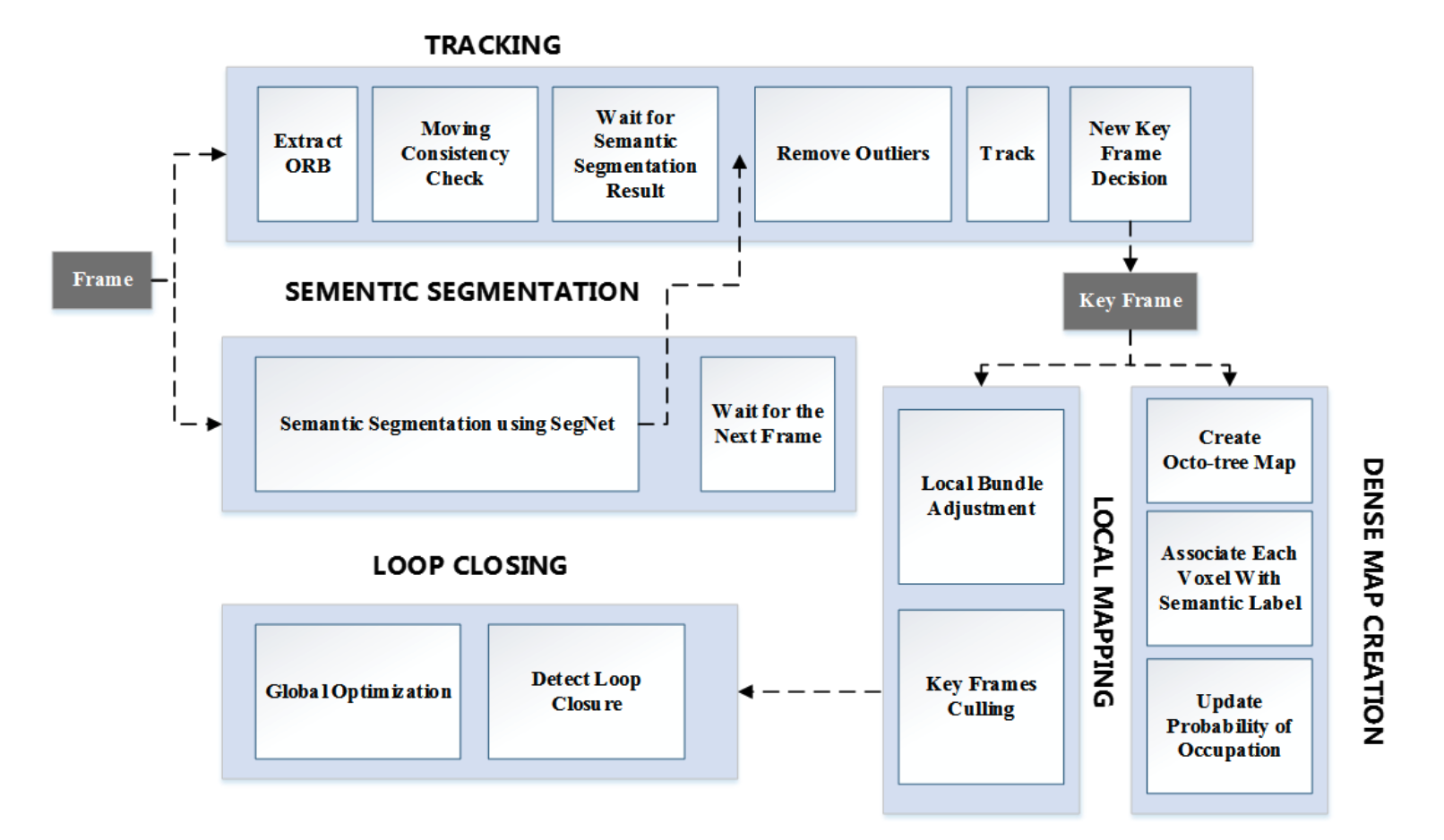
DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2018)
·
2018